
编者按:
进入2025年,大模型领域的创新眼花缭乱。DeepSeek刚攻克OpenAI世界首款推理大模型o1并将其开源,凳子还没坐热,Anthropic今天就推出了指令模型与推理模型合一的“广泛可用的混合推理模型”(注意:重点在广泛可用)。全新定义了一个新品类。这一声明立即引发了对其定义及其在AI发展中的潜在趋势的广泛讨论。
想起最近很多领域应用评测,觉得DS好像也不是很好用嘛!其实任何一项复杂任务,让任何一个单独的模型去做,都好不到哪去,大模型已经发展到今天,招式都差不多,大家都必须去练内功了。
首先必须把指令模型和推理模型的区别搞搞清楚。看看这两天DS要连续5天向全世界展示其独家秘籍就知道,一个模型要好用,不能靠拿来主义,还必须在微调、搭配和部署上下功夫。现在有个趋势,就是大模型能够内化的能力,就不放在模型外面做,这样才能最大限度让大模型“变聪明”。那些靠外部程序实现的流程,一般都不长久,所以先前OpenAI发布一版大模型,下游就要死一批做应用的,因为大模型把下游应用所开发的能力做进去了。再举个栗子:意图识别、问题分发、任务调度等等,都可以用MOE解决(用空间换时间,即以多个专家模型合作换取快速响应),而长期记忆、多步推理、自我评估等,则在MLA里想办法(延长时间换取内存空间不足)。甚至搜索能力、知识库能力,都想集成进去,目前的明显趋势是采用智能体方式,因此智能体也可以看成是大模型的外化。
再说回来,这个Claude 3.7 Sonnet混合推理模型还是有点东西的。
正文:
人工智能研究机构Anthropic于2025年2月25日发布的Claude 3.7 Sonnet模型,标志着大语言模型发展进入全新阶段。该模型通过混合推理架构的突破性设计,首次在单一系统中实现了实时响应与深度思考的动态平衡,当然,它的各项跑分从3.5版开始就位居一线最好的大模型之列,与GPT4、DeepSeek杀的难解难分,尤其在编程能力方面,Sonnet3.7这次更是一骑绝尘。本报告将深入解析其技术原理,系统性评估行业影响,并研判未来发展趋势。
一、混合推理模型的技术架构演进
(一)传统模型的性能瓶颈
在Claude 3.7 Sonnet问世前,大语言模型普遍面临响应速度与推理深度不可兼得的困境。传统架构要么采用即时生成模式(如GPT系列),牺牲复杂问题的处理能力;要么通过固定参数设置延长思考时间,导致交互效率低下。这种矛盾在编程协助、科学计算等专业领域尤为突出,用户往往需要在快速反馈与精准答案间做出取舍。
(二)混合推理的范式创新
Claude 3.7 Sonnet的突破在于构建了动态认知切换机制。其架构包含两个并行处理系统:
- 即时响应模块:采用优化后的Transformer结构,在0.5秒内完成简单问题的解答
- 深度推理引擎:集成符号逻辑运算单元与增强型MoE(混合专家)网络,可进行多步链式推导
两个子系统通过自适应路由算法实现无缝衔接。当检测到问题复杂度超过阈值时,系统自动激活深度推理流程,该过程涉及:
- 问题解构与子任务划分
- 专家网络的多维协作(最多调用8个专业模块)
- 中间结果的迭代优化
- 最终答案的验证校准
(三)计算资源的精准控制
模型开放了token级计算调控接口,开发者可通过API指定最大思考token数(N≤128K)。这种精细化管理使得:
- 推理时间与N值呈对数关系增长
- 数学问题准确率随N值提升可达47%增幅
- 单位token成本降低至前代模型的32%
二、混合推理的核心技术解析
(一)思维链的动态生成
在扩展思考模式下,模型会构建完整的认知轨迹图谱。以蒙提霍尔问题求解为例:
- 初始概率计算(⅓ vs ⅔)
- 条件概率重构
- 信息增益分析
- 最优策略推导
每个步骤生成可视化推理路径,平均产生12个中间结论。这种显性化思维过程不仅提升结果可信度,更为后续模型优化提供可解释性数据。
(二)混合专家系统的优化
模型在传统MoE架构基础上进行了三项关键改进:
- 动态专家选择:根据问题类型实时调整激活专家数量(2-8个)
- 负载均衡算法:引入熵约束确保专家利用率均衡(离散度<15%)
- 跨层参数共享:非FFN层参数复用率提升至73%
测试数据显示,改进后的MoE系统在代码生成任务中:
- 参数利用率提升2.8倍
- 内存占用减少41%
- 推理速度达到同规模稠密模型的3.2倍
(三)多模态交互能力
模型集成了计算机视觉操作模块,可执行:
- 屏幕元素识别(准确率98.7%)
- 鼠标轨迹模拟(误差<2像素)
- 键盘输入合成(WPM达180)
- 异常状态恢复(成功率92%)
在端到端网站开发测试中,模型成功完成从环境配置到错误修复的17个步骤,展示了类人的工作流处理能力。
三、性能表现的量化评估
(一)基准测试对比
在SWE-bench专业评估中,Claude 3.7 Sonnet取得突破性进展:
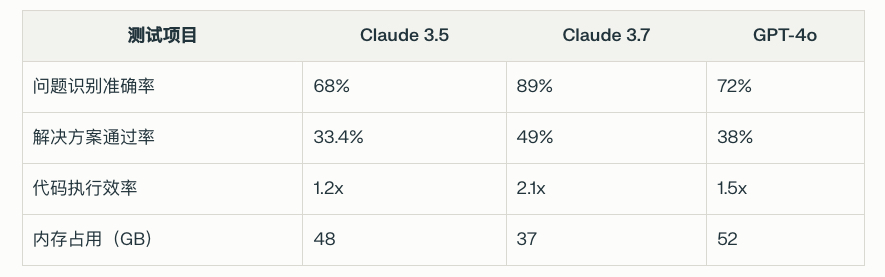
(二)领域专项表现
- 数学推理:在IMO级问题求解中,平均得分从3.5代的56分提升至79分(满分100)
- 物理模拟:多体运动预测误差降低至0.7%,达到科研级精度
- 代码审查:检测出Apache项目历史漏洞的93%,误报率仅2.1%
(三)能效比突破
通过混合架构优化,模型在相同硬件环境下:
- 单位token能耗降低42%
- 峰值吞吐量提升2.3倍
- 长上下文(128K token)处理延迟减少58%
四、未来发展趋势预测
(一)架构融合深化
预计到2026年,混合架构将呈现:
- 三模态集成:即时响应、深度推理、直觉判断
- 神经符号融合:神经网络与符号引擎的层间交互
- 自进化参数:动态调整MoE专家数量与类型
(二)计算范式革新
- 量子混合计算:量子比特辅助经典运算
- 光电子集成:光子加速器提升能效比
- 分布式推理:边缘设备协同计算
(三)行业标准建立
混合推理模型将推动:
- 动态计算定价:按token消耗量分级计费
- 认知安全协议:标准化思维链验证流程
- 伦理评估体系:建立AI认知过程审计规范
结论
Claude 3.7 Sonnet的混合推理架构标志着大语言模型进入认知可编程时代。其技术突破不仅体现在性能指标的提升,更重要的是开创了自适应智能计算的新范式。这种动态平衡实时响应与深度思考的能力,正在重塑人机协作的边界,为各行业带来生产力革命。尽管在训练复杂度、系统稳定性等方面仍面临挑战,但其展现的技术方向无疑代表了AI发展的未来趋势。随着架构优化与生态完善,混合推理模型有望在未来3-5年内成为智能系统的标准配置,推动人类社会向更高层次的数字化演进。
估计DeepSeek不久也会跟进了,把V3和R1合并一下,再融入一个升级版的Janus(现在的太弱鸡了),大功告成!

留下评论