
如果我告诉你,早在人类刚提出“人工智能”概念时,便开启了以神经网络模拟人类智能的尝试,你会不会觉得吃惊?今天,这类大模型以最快的速度普及,几乎已经成为我们日常生活的一部分,它们能够生成流畅的文本,回答各种各样的问题,进行创造性的写作,其智能程度在很多方面超过了平常人类,然而,令人惊讶的是,它的基本原理和很多细节在上世纪中叶就已经被提出,经过长时间被认为是毫无可能的科学幻想之后,忽然得到了实现,这背后经历了怎样的发展历程?又有哪些深层原理至今仍是未解之谜?
1958年的惊人预言:《纽约时报》与“会思考的机器”
1958年,《纽约时报》刊登了一篇题为“新海军设备通过实践学习”的文章,报道了美国海军的一项新发明——“感知器”(Perceptron)。这篇文章以充满乐观的口吻宣称,海军拥有了一个“会思考的机器”的“胚胎”,并大胆预测,这个机器未来将能够“行走、说话、看、写字、自我复制,并意识到自己的存在”。这篇报道充满了对人工智能早期发展的兴奋和憧憬,将感知器比作一个计算机的“胚胎”,暗示着这项技术拥有着无限的潜力。当时的人们对这项新技术寄予厚望,甚至认为人工智能时代即将到来。
然而,回顾历史,我们发现当时的预测与感知器实际的能力之间存在巨大的差距。尽管如此,这篇文章却捕捉到了早期人工智能研究的雄心壮志,以及将机器变得像人类一样智能的愿景。将当时的预言与今天的技术进行对比,能够清晰地展现人工智能领域所取得的巨大进步,以及最初的梦想虽然简陋,但却是惊人的伟大。
神经网络的萌芽:Perceptron的基本原理
感知器是由弗兰克·罗森布拉特(Frank Rosenblatt)发明的,它被认为是现代深度神经网络的早期雏形1。其核心思想是让计算机通过模仿人脑神经网络的方式进行学习和推理。感知器的基本功能是作为一个学习机器,能够将输入的信息分类到两个不同的类别中。
感知器的结构受到人脑神经元的启发,由多个相互连接的节点组成。每个输入都与一个权重相关联,感知器会根据这些权重以及一个偏置项来计算输出。关键在于,感知器能够根据其预测是否正确来调整这些连接的权重,这是一种早期的机器学习形式。罗森布拉特的感知器模型包含三种基本单元:“投影”单元(AI)、“关联”单元(AII)和“响应”单元(R)。感知器的这种通过调整连接强度来学习的方式,为后来更复杂的神经网络奠定了基础。例如,早期的感知器甚至能够通过学习区分照片中的男性和女性。
漫长的蛰伏:从科学幻想走向深度学习
在最初对感知器的乐观预期之后,人工智能领域经历了一段相对缓慢的发展时期,被称为“AI寒冬”。尽管感知器在某些简单的分类任务上取得了一些成功,但很快人们就意识到,实现真正的人工智能远比想象的要复杂得多。当时如日中天的专家马文·明斯基(Marvin Minsky)对感知器的能力提出了强烈的质疑,指出早期的AI系统缺乏关键性的数学能力(无法处理异或问题),而这对于人类来说却是轻而易举的事情。
然而,总有一些有坚定信仰的人在负重前行,神经网络的研究并没有完全停止。随着计算能力的提升和互联网的普及,获取大量数据变得更加容易,这为神经网络的复兴创造了条件。研究人员开始探索更复杂、更动态、更数字化的神经网络模型,这最终促成了深度学习的突破。
Hinton等人的关键贡献:深度学习的突破
杰弗里·辛顿(Geoffrey Hinton)被誉为“深度学习之父”,他在推动人工智能从科学幻想走向现实的过程中发挥了至关重要的作用11。他在深度学习领域的贡献是开创性的:
- 反向传播算法:20世纪80年代,辛顿与他人共同开发了反向传播算法。这项技术通过有效地调整神经网络内部参数,彻底改变了深度神经网络的训练方式,为训练多层神经网络提供了可行的途径。
- 玻尔兹曼机:辛顿还共同发明了玻尔兹曼机,这是一种随机神经网络模型,在无监督学习领域发挥了重要作用。这也成了辛顿获得2024年诺贝尔物理学奖的重要原因。
- 深度信念网络:他在2006年发表的论文展示了如何通过逐层预训练来有效地训练深度神经网络,这重新燃起了人们对神经网络的兴趣。
- 语音和图像识别的突破:辛顿的研究团队在使用深度神经网络进行语音识别和物体分类方面取得了重大突破,证明了深度学习在实际应用中的巨大潜力。
- 胶囊网络:近年来,辛顿还在不断探索新的神经网络架构,例如胶囊网络。
由于其在深度学习领域的开创性贡献,辛顿与约书亚·本吉奥(Yoshua Bengio)和杨立昆(Yann LeCun)共同获得了2018年的图灵奖。他至今仍然活跃在人工智能研究的前沿,警醒人们通用人工智能和超级人工智能的到来将可能带来巨大的风险。
今日的辉煌:基于深度神经网络的大语言模型
如今,基于深度神经网络的大语言模型,如GPT-3、GPT-4、DeepSeek等,展现出了令人瞩目的能力。它们不仅能够生成高度逼真的人类文本,还能回答问题、总结文档、翻译语言,甚至生成代码18。这些模型被广泛应用于内容创作、客户服务(聊天机器人)、语言翻译、科学研究、甚至医疗诊断等多个领域。
以GPT-4为例,它不仅可以处理文本输入,还可以接受图像输入,实现多模态交互。它拥有更大的上下文窗口,能够处理更长的文本,并且在推理和对话能力上都有显著提升。GPT-4在多项标准化考试中都表现出了接近甚至超越人类的水平。从最初感知器的简单二分类任务,到如今大语言模型复杂的文本生成和理解能力,这体现了神经网络架构、训练数据规模和计算能力的巨大飞跃。大语言模型在各个领域的广泛应用,也预示着它们将深刻地改变我们的生活和工作方式。
梦想照进现实?对比1958与今日
让我们再次回顾1958年《纽约时报》对“会思考的机器”的预测,并与今天的大语言模型进行比较:
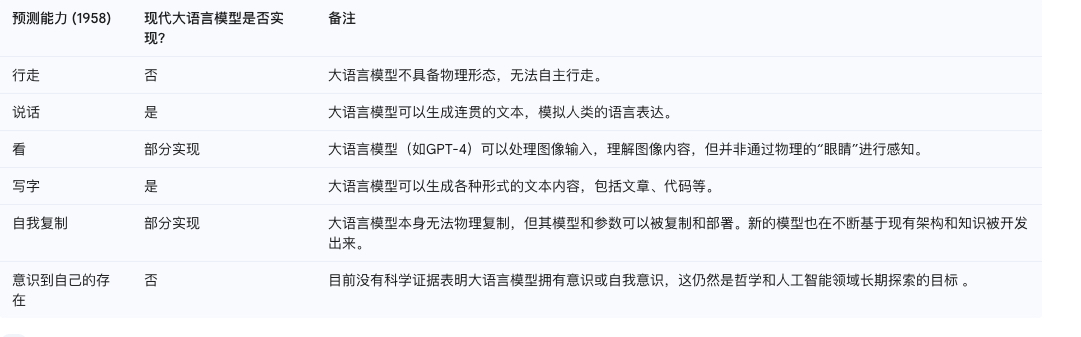
从上表可以看出,尽管现代大语言模型在“说话”和“写字”方面取得了显著的进展,甚至在某种程度上实现了“看”的能力,但“行走”、“自我复制”和“意识到自己的存在”等预测,要么尚未实现,要么与最初的设想存在差异。这反映了实现通用人工智能的复杂性和挑战性。
未解之谜:大语言模型为何如此强大?
尽管大语言模型取得了巨大的成功,但其深层原理仍然存在争议或未被完全理解2。这主要归因于以下几个方面:
- 模型的复杂性:现代大语言模型拥有数十亿甚至数万亿的参数。如此庞大的参数量使得我们难以完全理解这些参数是如何相互作用,从而产生如此复杂的行为。模型的内部运作机制就像一个巨大的黑箱,我们很难完全追踪其决策过程。
- 涌现能力:大语言模型在规模扩大和接受海量数据训练后,会涌现出一些意想不到的能力,例如进行复杂的推理、理解上下文、甚至进行创造性写作。这些能力并非通过显式编程实现,而是自发产生的,其内在机制尚不完全清楚。这种突如其来的能力增强令人惊讶,也增加了理解模型原理的难度。
- 内部表征的不可解释性:尽管我们可以观察到大语言模型的输入和输出,但模型内部学习到的知识和表征方式往往难以被人类直接理解。我们很难知道模型是如何在内部表示和处理语言信息的,这使得我们难以解释其行为背后的“思考”过程。
正是由于这些复杂性和涌现性,尽管我们能够使用大语言模型并观察到它们强大的功能,但对其工作原理的深层理解仍然是一个正在进行的研究课题。
总结与展望:AI的过去、现在与未来
从1958年《纽约时报》对“会思考的机器”的惊人预言,到今天深度神经网络大语言模型的辉煌成就,人工智能走过了一段漫长而激动人心的旅程。像杰弗里·辛顿这样的先驱者,通过他们的不懈努力,将曾经的科学幻想逐渐变成了现实。
尽管我们已经取得了显著的进步,但我们仍然面临着许多未解之谜。大语言模型为何如此强大?它们是否真的理解语言?它们距离真正的通用人工智能还有多远?这些问题仍然吸引着无数研究人员不断探索。人工智能的未来充满了机遇和挑战,我们有理由相信,随着技术的不断发展,我们终将更深入地理解智能的本质,并创造出更加强大和有益的人工智能系统。



留下评论