
摘要
据说AI大神Andrej Karpathy 在社交媒体上留言“请停止MCP”(即Anthropic推出的模型上下文协议MCP)。作为一位与伊利亚肩并肩开创OpenAI大模型新天地,又跟马斯克打下X.AI基础的AI大佬,他的观点必须引起重视。但可能碍于江湖规则,他也不能多说什么,所以只能在这里猜测一下。
MCP 被一些人视为 AI 集成的重要进步,而 Karpathy 的观点可能被视为对这种方法的挑战。证据倾向于认为,可能他认为 MCP 增加了不必要的复杂性或效率低下,而他更倾向于直接优化数据以适应大型语言模型(LLM)的上下文窗口,而不是使用像 MCP 这样的协议来连接外部数据源。
背景
Andrej Karpathy 是 AI 领域的知名人物,曾是 OpenAI 的联合创始人,并在 Tesla 领导自动驾驶 AI 团队。他最近对 Anthropic 的 MCP 表示不满,在 2025 年 3 月 12 日的一条 X 帖子中回复“请让它停下来”,这表明他不赞成该协议。
可能的原因
Karpathy 可能认为,相比通过 MCP 动态获取数据,将数据预先格式化以直接放入 LLM 的上下文窗口更有效。他在其他讨论中提到,文档应为 LLM 设计,例如使用单一 markdown 文件,这可能反映他更喜欢简单直接的方法,而不是复杂的协议。
此外,他可能担心 MCP 会引入延迟或安全问题,但这些只是推测,因为他没有详细说明原因。
有趣的是,Karpathy 的评论是在一个关于 LLM 内容优化的讨论中提出的,这表明他的反对可能与他对 AI 数据处理的整体哲学有关,而不仅仅是 MCP 本身。
详细分析
Andrej Karpathy 对 Anthropic 的模型上下文协议(MCP)的负面看法引发了广泛关注,尤其是在 2025 年 3 月 12 日的一条 X 帖子中,他回复“请让它停下来”,这表明他希望该协议停止发展。本文将深入分析他可能的不满原因,并结合他的公开言论和 AI 领域的背景,提供全面的视角。
MCP 的概述
首先,了解 MCP 的本质是关键。根据 Anthropic 的官方文档,MCP 是一个开放标准,旨在将 AI 助手连接到数据系统,如内容库、业务工具和开发环境。其目标是帮助前沿模型生成更相关、更准确的响应,例如通过预构建的服务器连接 Google Drive 和 Slack 等平台 (Model Context Protocol)。
MCP 通过客户端-服务器架构工作,包括通信层以确保安全的数据交换,旨在解决 AI 与数据源隔离的问题,取代碎片化的自定义集成 (Introducing the Model Context Protocol)。这被一些开发者视为 AI 集成的重大进步,例如在 Reddit 上,有人称其为“游戏规则改变者”,因为它标准化了数据访问 (r/ClaudeAI on Reddit)。
Karpathy 的评论背景
Karpathy 的评论出现在 2025 年 3 月 12 日的一条 X 帖子中,当时一位用户询问他对 MCP 的看法,他回复“请让它停下来”,并附上一张表达疲惫的图片 (X post)。这一回复的语气表明他可能对 MCP 的理念或实施感到不满,但未提供具体原因。为了理解他的立场,需要结合他近期对 LLM 的看法。在同一 X 帖子线程中,他提到 2025 年大部分内容仍是为人类设计的,而 99.9% 的注意力将转向 LLM 注意力,例如文档应为 LLM 的上下文窗口设计,如单一 markdown 文件 (X post)。这可能暗示他更倾向于数据预优化,而不是通过协议动态获取。
可能的不满原因
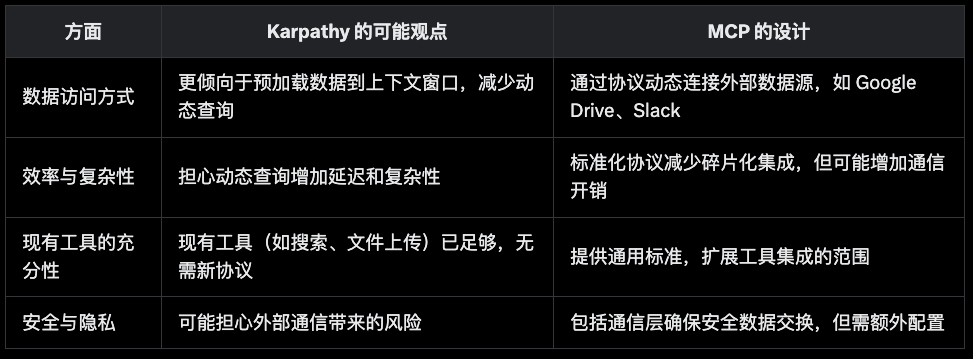
基于他的言论和 AI 领域的背景,可以推测以下几个可能的原因:
- 效率与复杂性:Karpathy 可能认为 MCP 增加了不必要的复杂性。LLM 的上下文窗口本身可以作为工作内存,通过检索增强生成(RAG)访问相关文档,这在“Deep Dive into LLMs like ChatGPT”的总结中有所体现 (Deep dive into LLMs like ChatGPT by Andrej Karpathy (TL;DR))。例如,上下文窗口的长度(如 GPT-4 的 128k 令牌)决定了模型的计算成本,动态查询可能引入延迟,而预加载数据可能更高效。
- 现有工具的充分性:从“How I use LLMs”的总结来看,Karpathy 强调 LLM 与工具的集成,如互联网搜索、Python 解释器和文件上传,这些工具的结果直接添加到上下文窗口中 (How I use LLMs by Andrej Karpathy)。例如,互联网搜索可以通过特殊令牌触发,处理实时数据(如股票价格),这可能让他认为现有的方法已足够,无需新的协议。
- 哲学与设计偏好:Karpathy 可能更倾向于数据预格式化,而不是依赖协议。他在视频中提到,文档应为 LLM 设计,例如使用 markdown 文件,这与 MCP 的动态连接数据源的理念相悖。他可能认为,预优化数据能更好地利用 LLM 的能力,而 MCP 可能增加不必要的抽象层。
- 潜在的技术担忧:虽然未明确提及,Karpathy 可能担心 MCP 的安全性和隐私问题。例如,MCP 需要与外部系统通信,这可能带来数据泄露风险,而直接加载本地格式化的数据可能更安全。
对比与争议
MCP 被一些人视为 AI 集成的突破,例如 Forbes 文章称其为“AI 代理演化的重要一步”,因为它简化了与多种数据源的连接 (Why Anthropic’s Model Context Protocol Is A Big Step In The Evolution Of AI Agents)。然而,Karpathy 的反对可能引发争议,因为他的观点代表了 AI 社区中对数据集成方法的多样化看法。他的立场可能被视为对标准化协议的挑战,尤其是在开发者社区中,有人认为 MCP 解决了自定义集成的维护噩梦。
详细分析表
以下表格总结了 Karpathy 可能的不满原因及其与 MCP 的对比:
结论
综合来看,Andrej Karpathy 不看好 MCP,可能因为他更倾向于直接优化数据以适应 LLM 的上下文窗口,而不是通过协议动态连接外部系统。他的观点可能反映了他对 AI 数据处理的整体哲学,即简化流程、提高效率。然而,由于他未详细说明原因,这些推测基于他的公开言论和 AI 领域的背景,需进一步观察他是否会提供更多解释。

留下评论