
by ChatGPT
【分别请Perplexity和ChatGPT做了一周小结,大家可以比较。这里是ChatGPT版本】
过去一周,人工智能圈子又热闹非凡,简直卷出了新高度。从超强大的新模型同台竞技,到各种新工具扎堆上线;从开源势力不甘示弱、硬件大佬秀肌肉,到AI在现实场景中的深度渗透,以及巨额资本争相入局……这一连串AI新闻让人眼花缭乱。下面我们就用轻松的方式,带大家快速回顾一下这一周AI界发生的那些大事件。
模型比武大会
本周的模型圈俨然举行了一场“武林大会”,各家顶级AI模型纷纷登场亮绝活。谷歌祭出了号称有史以来最能“动脑筋”的Gemini 2.5 Pro,腾讯升级发布了自研大模型混元T1高调挑战 OpenAI 和 DeepSeek,而开源界的代表DeepSeek R1也不遑多让,场面堪称神仙打架。
先说谷歌的Gemini 2.5 Pro。这款新模型可谓模型界的“大胃王”,因为它拥有令人瞠目的超长上下文窗口——整整100万个 token!(官方计划后续扩展到200万)。也就是说,它一次性“吃”下一本书都不是问题,处理长文档再也不需要拆成碎片。凭借过人的“胃口”和推理能力,Gemini 2.5 Pro 在多个基准测试上都秀出了肌肉,把对手 OpenAI、Anthropic、DeepSeek 等模型比了下去。例如,在 2025 年 AIME 数学竞赛中拿下86.7%的高分,在科学问答 GPQA 基准上取得84.0%,在综合性难题测试 Humanity’s Last Exam 中更是比第二名高出18.8个百分点。而这些成绩据说是在没有借助额外测试时增强技巧的情况下达成的,足见模型实力之强。再看编程能力,Gemini 2.5 Pro 的表现也可圈可点:在 Aider Polyglot 代码编辑基准上取得了68.6%(另有说法是74.0%)的成绩,超过了绝大多数竞品;不过在更广泛的 SWE-Bench Verified 编程挑战中得分63.8%,稍逊于 Anthropic 的 Claude 3.7 Sonnet,屈居第二。尽管如此,谷歌表示 Gemini 2.5 Pro 在创建带酷炫前端界面的 Web 应用和编写智能代理程序方面依然表现出色。更厉害的是,Gemini 2.5 Pro 还是个多模态选手:文本、图像、音频、视频它都能当输入(目前输出还只能是文字)。它被谷歌称作“思考模型”,特别擅长编码、数学、逻辑和科学推理,还具备工具使用能力——比如可以调用外部函数、输出结构化的 JSON、执行代码甚至上网搜索。简单说,Gemini 2.5 Pro 脑子活、有知识、胃口大,俨然是AI模型里的卷王。
再来看腾讯的混元 T1。腾讯这边也不示弱,推出了升级版大模型“混元 T1”,直接对标国际先进模型。据介绍,T1 基于自研的 TurboS 架构,号称全球首个超大规模混合 Transformer-MoE 架构模型(内部代号“Mamba”)。这套 “Mamba” 架构专为长文本优化,能够高效捕获长序列中的信息,同时降低计算开销。得益于架构优势,T1 在相同部署条件下的解码速度据称是同级别模型的两倍,生成速度达到60-80token/秒,直接碾压 GPT-4.5 和 DeepSeek R1 等对手。那它的实力到底如何呢?腾讯给出了一系列内部评测数据:在综合知识测试 MMLU-PRO 上得分87.2(略低于 OpenAI 顶级模型),专业科学问答 GPQA-diamond 得69.3,代码基准 LiveCodeBench 得64.9,数学挑战 MATH-500 高达96.2(与 DeepSeek R1 旗鼓相当),复杂推理 ArenaHard 任务91.9。这些成绩表明,混元 T1 在知识、推理、数学等方面已经和业内最顶尖模型打成平手,一些场景甚至还有优势。尤其值得一提的是它的响应速度,据现场演示反馈,面对复杂数学题时 T1 作答速度明显快过 DeepSeek R1,堪称又快又准。一些第三方报告甚至声称混元 T1 在大多数基准测试中全面优于 DeepSeek R1 和 GPT-4.5,可见这位中国AI新秀来势汹汹。腾讯还强调 T1 在文化创意指令跟随、文本摘要和智能代理等能力上表现突出。总的来看,这款模型的目标直指 OpenAI 和 DeepSeek 等顶尖选手,中国AI卷王的野心可见一斑。
最后说说开源阵营的DeepSeek R1。作为当前开源社区的最强代表之一,DeepSeek R1 其实早已名声在外:它拥有6710亿参数的惊人规模,以强大的推理能力和处理长篇内容的本领而闻名。截至今年1月,DeepSeek R1 在 Chatbot Arena 全球对话模型排行榜中高居第四名,是表现最好的开源模型(可谓“开源之光”)。据称,DeepSeek R1 通过大规模强化学习强化了逻辑推理,本身的成本效益也非常突出——相较 OpenAI 的顶级模型,它的使用成本低约30 倍,运行速度快5 倍。在复杂模式识别任务中(如基因组数据分析、医学影像解读、大规模科学模拟),R1 展现出卓越的精度。最近,DeepSeek R1 已经登陆 AWS 云服务,作为 Amazon Bedrock 上完全托管的无服务器模型供客户使用。这意味着企业可以轻松将其用于生产部署。凭借在复杂问题求解、代码编写、数据分析和多语言翻译等方面的出色表现,外加开源的特性和云平台上的便捷使用,DeepSeek R1 成为许多场景下专有闭源模型的强大且高性价比的替代方案。
我们不妨把以上几位选手的一些关键指标列在一起对比看看:
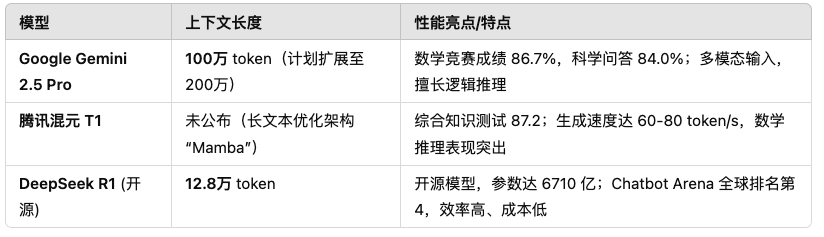
可以看出,在这场模型比武大会中,各家模型你追我赶:Gemini 2.5 Pro 以超长上下文和推理实力称雄,混元 T1 则凭借速度优势和全面表现后来居上,DeepSeek R1 依靠开源与效率稳居一席之地。模型的卷王之争,正变得愈发精彩。
新晋工具亮相
模型大战正酣的同时,各种新工具和新功能也在迅速涌现,为AI应用添砖加瓦,包括但不限于:
- 谷歌 Colab 数据科学代理:谷歌在 Colab 平台中内置了一个数据科学 AI 小助手,相当于给程序员配了个聪明的助手。写代码时,它可以帮忙自动处理数据分析任务,理解指令意图,从而让研究过程更加轻松高效。以后在 Colab 里写笔记本,不仅有人帮调代码,还有AI陪聊,一边写程序一边“对话”搞定分析工作,想想都很酷。
- Claude 网页搜索功能:Anthropic 公司的 Claude 聊天机器人如今也学会了“上网冲浪”。他们为 Claude 新增了由 Brave Search 提供支持的网页搜索功能,目前对美国地区的付费用户开放测试版。有了这项技能,Claude 回答需要最新资讯的问题时就更加游刃有余,不再害怕知识截止于训练数据,真正变成了一个“爱上网的AI”。
- 微软 Copilot Researcher:微软则为其 365 Copilot 办公AI助手推出了新的“研究员”(Researcher)和“分析员”功能模块。简单来说,在写文档或做报告时,Copilot 现在可以帮你自动查找资料、汇总信息,甚至分析数据,俨然一个贴身AI研究助理。这将大大提升办公生产力——以后写方案写论文,直接让 Copilot 去帮忙搜集素材和数据分析,你只管动脑创意,其它杂活AI全包了。
这些新工具的陆续登场,说明各大厂商都在飞快地为自家AI配备新技能:从写代码到查资料、从数据分析到上网找答案,AI助手正变得越来越全能,真可谓八仙过海各显神通。
开源势力崛起
在巨头混战的同时,开源社区的 AI 势力也在蓬勃崛起,可没有打酱油。首先不得不提DeepSeek R1。正如前文所述,DeepSeek R1 是当前最强的开源大模型之一,拥有6710 亿参数的恐怖体量,凭借超强的推理能力和长文本处理本领,在业内刷足了存在感。它在今年年初的 Chatbot Arena 排行榜中名列全球第4,在所有开源模型中拔得头筹,称得上是“开源之光”。DeepSeek R1 通过大规模强化学习侧重训练了逻辑推理能力。据报道,相比 OpenAI 的顶级模型,它要便宜30 倍、运行速度快5 倍,性能和效率都相当惊人。在一些复杂任务上(例如基因组数据分析、医学成像诊断、大规模科学模拟等),R1 展现出远超以往的准确性。更令人兴奋的是,DeepSeek R1 如今已作为完全托管的无服务器模型登陆 AWS 的 Bedrock 平台。这意味着开发者和企业用户在云端就能轻松调用这个开源大模型,在解决复杂问题、编写代码、数据分析、多语言翻译等方面充分受益。开源的特性加上云端的易用性,让 R1 成为闭源模型之外一股不容小觑的力量。
值得一提的是,国内大厂也开始拥抱开源。腾讯不仅将开源的 DeepSeek R1 集成到了自家产品(如 “猿宝” 应用)中,还表示很快会开放一款性能与其旗舰模型相当的中等规模模型,与社区共享成果。这意味着我们有望见到更多像 Llama2 那样由大公司主导开源的强力模型出现。像腾讯 T1 所采用的新架构 “Mamba” 也是一种创新尝试,如果未来类似技术开放出来,将进一步提升开源模型的实力。此外,各种开源中型模型最近也是层出不穷,新架构、新算法在社区中百花齐放,加速了技术普及。总的来看,开源AI正在快速崛起,与巨头们形成了一种此消彼长的竞合关系:你有你的闭源王牌,我有我的开源杀手锏。未来的AI江湖,既会有高墙花园里的霸主,也会有开源草原上的群雄逐鹿。
硬件肌肉秀
说完软件和模型,再来看看硬件圈。本周硬件巨头们也在秀肌肉,让AI拥有更强悍的“体格”。
(NVIDIA Blackwell Ultra AI Factory Platform Paves Way for Age of AI Reasoning | NVIDIA Newsroom)NVIDIA 推出的 Blackwell Ultra 人工智能工厂平台,堪称 GPU 界的“肌肉猛男”。这套庞然大物采用了机架级的一体化设计:一台系统里塞入72块 Blackwell Ultra GPU 和36个基于 Arm 架构的 Grace CPU 联合作战,提供惊人的算力。相比上一代组合 (NVIDIA GB200 NVL72),新的 GB300 NVL72 整体 AI 性能提升了约1.5 倍。Blackwell Ultra 平台增强了训练和推理时的扩展能力,专为大规模 AI 推理、智能代理和“物理AI”(如机器人智能)等应用优化。有了这样强悍的硬件“底座”,模型在部署时可以实现更高的吞吐量、更快的响应速度,并降低总体成本。一句话:这是给 AI 装上了超强动力引擎,让大模型跑得更快、更稳。
(NVIDIA Announces Isaac GR00T N1 — the World’s First Open Humanoid Robot Foundation Model — and Simulation Frameworks to Speed Robot Development | NVIDIA Newsroom)另外,英伟达还发布了全球首个用于通用人形机器人的基础模型——NVIDIA Isaac GR00T N1。这实际上是一个开放的机器人“大脑”模型,赋予人形机器人通用的技能和推理能力,标志着物理世界的 AI 再进一步。有了 Isaac GR00T N1,再配合仿真训练框架,开发者可以更轻松地定制和训练人形机器人,让机器人学会做饭、搬箱子、医疗看护甚至紧急救援等各种复杂任务。据悉,为了加速这类机器人“大脑”的研发,英伟达还联合 Google DeepMind 和迪士尼研究院开发了新一代开源物理引擎,并推出 Omniverse 的合成数据生成工具,为训练机器人提供了强大的模拟环境支持。值得注意的是,人形机器人市场被看好——预计到 2029 年全球市场规模将达到132.5亿美元 ,物流、医疗、搜救等领域对人形机器人的需求正不断增长。有了像 Blackwell Ultra 这样的强劲算力“身躯”和 Isaac N1 这样的智能“头脑”,科幻中的人形机器人走进现实似乎也不那么遥远了。
AI走进现实
AI 技术不仅在实验室里突破,在现实世界的方方面面也开始发挥越来越大的作用:
量子计算与 AI:在人们探索的前沿方向中,量子计算+AI 是备受关注的一项。2025 年被定为“国际量子年”,全球都在关注量子科技的突破如何影响各领域。有研究团队在 2024 年表明,将量子计算融入神经网络训练有潜力显著加速 AI 模型的训练。当然,真正实用的“量子 AI”可能还需要不少时间。英伟达 CEO 黄仁勋就认为,有用的量子计算还得等15-30年。不过业界已经在积极尝试了——在英伟达 GTC 2025 大会上,就有专门小组讨论了量子算法和硬件加速 AI 的最新进展 。尽管实际应用尚处早期,但这种跨界融合前景令人期待:也许未来那些经典计算机难以解决的复杂问题,交给量子计算就能手到擒来,从而为 AI 提速,带来新的突破。
AI 医疗诊断:在医疗领域,AI 正在卷起袖子大干一场。美国缅因大学的研究人员开发出了一种名为CGS-Net的先进模型,通过模拟病理学家分析组织切片的方式,大幅提高了乳腺癌诊断的准确率。据报道,这套 AI 系统对癌症的检出率接近100%,轻松超过人类医生的平均水平。这意味着,在不久的将来,AI 有望辅助医生更早更准地发现癌变,挽救更多生命。可见在医学影像和疾病筛查方面,AI 正展现出前所未有的潜力。一些国际研究团队也在推出新模型(如ECgMPL等),不断刷新着医疗诊断 AI 的记录。相信随着技术成熟,AI 将成为医生在诊断过程中的得力助手。
软件开发与推理:在软件开发领域,AI 也已经成为程序员的好伙伴。越来越多开发者使用 GitHub Copilot、TabNine、Codeium 等 AI 编码助手来提高效率——自动补全代码、生成函数,让敲代码如有神助。不过,新的问题也随之而来:AI 生成的代码可能隐藏 bug 甚至安全漏洞,代码安全和可靠性成为新的挑战。为此,开发者们也在想办法对策,比如最近出现的一个工具RepoScribe,可以将整个代码库导出融入 LLM 提示中,让 AI 对庞大的代码仓库进行深入分析和重构。有了这类工具辅助,团队就能更全面地检查 AI 写的代码,提升软件质量与安全性。另一方面,为了让 AI 更会“思考”,研究者们还在探索新的提示技术,比如链式思考 (Chain-of-Thought, CoT)提示。这种方法通过引导 AI 把复杂问题拆解成一系列步骤来逐步作答,相当于让 AI 学会像人一样有条理地“自言自语”推理 。实践证明,CoT 技术能显著提升 AI 解决复杂问题的正确率,让 AI 的回答更加合乎逻辑、更靠谱 。
AI 落地与机器人:在现实生活中,我们也开始看到越来越多 AI 驱动的应用和装置。以人形机器人为例,前面提到的 NVIDIA Isaac GR00T N1 等基础模型的推出,加上强大的计算硬件,使得机器人变得愈发聪明。市场研究预计到 2029 年,人形机器人市场规模将达到 132.5 亿美元,物流、医疗、服务、搜救等行业对于机器人助力都有庞大需求。随着 AI 技术的成熟,这些领域正在涌现更多智能自动化解决方案:比如仓库里由AI控制的机械臂在分拣包裹,医院里AI辅助的机器人在做简单检查,灾难现场机器人在AI指导下参与救援等等。可以预见,不久的将来,我们在工厂、医院甚至家里都能看到机器人忙碌的身影,AI 正真真切切地走进现实世界,改变我们的生活。
资本的味道
最后,再来闻闻“资本的味道”。AI领域的炙热发展自然引来了巨额真金白银的投入。这周有一条令人咋舌的新闻:阿拉伯联合酋长国(UAE)宣布将向美国投资1.4 万亿美元,重点投向人工智能、半导体、清洁能源等高科技领域。没错,万亿级别的资金涌入,只为在AI时代占据一席之地。这也从侧面反映了当前全球范围内建设 AI 基础设施的热潮:各国政府和科技巨头都在疯狂砸钱建数据中心、买GPU算力、抢AI人才,生怕在新一轮科技竞赛中落后半步。可以预见,有了资本的加持,未来 AI 的发展会进一步提速。一边是技术在卷疯了往前冲,一边是资本在源源不断加码,这股 AI 热潮恐怕短时间内是停不下来了。
总之,过去这一周 AI 领域可谓你方唱罢我登场:模型、工具、开源、硬件、应用、资本轮番上阵,热闹非凡。可以想见,接下来我们还将看到 AI 世界更多令人兴奋的新动态——毕竟AI 们现在真的卷疯了!


留下评论