数据可视化是数字人文结果呈现的重要手段,尤其应用于博物馆、美术馆以及历史文化遗产研究方面。然而可视化是一个非常考验艺术细胞和想象力的领域,也有相当的技术门槛,这里试图比较一下目前各类最先进的大语言模型在可视化方面的智商。结果显示:目前大模型竞争的主战场还没有卷到输出可视化,因此在可视化的智能实现方面尚属于只能使用大模型原生能力的非常初级阶段。
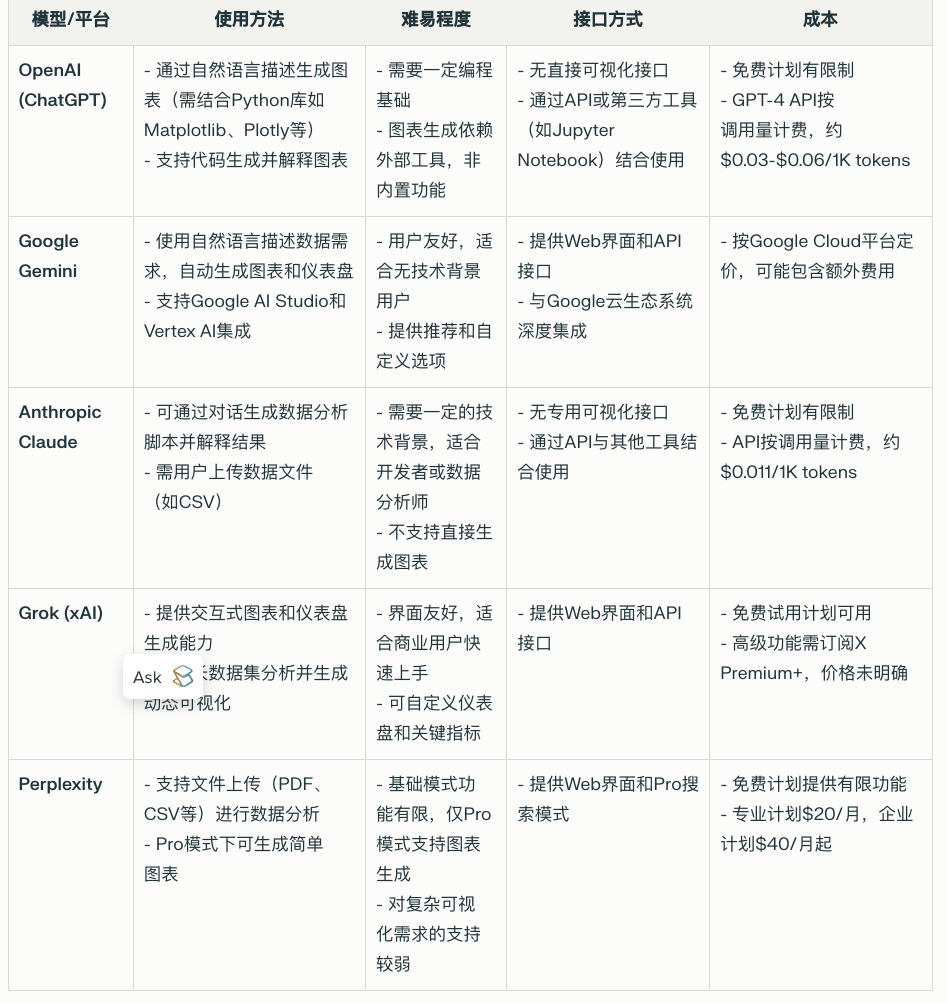
目前拥有顶尖(SOTA)大模型的几家主要公司(如 GPT-4、Gemini、Claude 等),在辅助创建信息可视化(Infographics)方面的能力很差,尚不能直接“生成”最终的、设计精美的、像素完美的“信息图”(Infographic)文件。它们的核心能力在于理解和生成文本、代码,以及一定程度的图像理解和生成,通常是单个图像元素,而非复杂的、数据驱动的布局。
因此,这些模型在创建信息图方面的作用更偏向于“智能助手”,在信息图的构思、内容撰写、数据处理建议、甚至代码生成(用于图表)等环节提供帮助,而不是一键生成最终成品。用户通常还需要结合专门的设计工具(如 Canva、Piktochart、Adobe Express、Figma 等)来完成最终的视觉设计和排版。
以下是几家主要公司及其模型在这方面的比较:
1. OpenAI (模型:GPT-4 / ChatGPT, DALL-E 3)
- 能力与使用方法:
- 内容生成:可以根据主题或数据,快速生成信息图的标题、引言、各个部分的说明文字、要点总结等。
- 结构规划:帮助用户构思信息图的逻辑流程和内容板块。
- 数据简化与解读:可以分析你提供的数据(尤其是使用 Advanced Data Analysis/Code Interpreter 功能),提取关键信息,并建议适合的可视化图表类型(如条形图、饼图、折线图等)。
- 生成简单图表代码:Code Interpreter 功能可以根据数据生成 Python 代码(使用 Matplotlib, Seaborn 等库)来创建基本的图表,这些图表可以截图使用或作为参考。
- 生成视觉元素:通过集成的 DALL-E 3,可以根据描述生成图标、插画等单个视觉元素,但将这些元素组合成完整、协调的信息图仍需手动操作。
- 创意启发:提供关于信息图布局、色彩搭配、风格等方面的建议。
- 使用 ChatGPT 进行文本生成、构思和提建议非常简单,就像聊天一样。
- 使用 Advanced Data Analysis 分析数据和生成图表代码需要一些基本的数据概念。
- 使用 DALL-E 生成合适的视觉元素需要有效的提示词(Prompt Engineering)。
- 整合所有内容到最终设计需要使用其他工具,增加了复杂度。
- ChatGPT Web/App 界面 (包括免费版、Plus/Team/Enterprise 版)。
- API (需要编程能力接入)。
- ChatGPT 免费版(基于 GPT-3.5,功能受限)。
- ChatGPT Plus/Team/Enterprise 订阅(约 20-30美元/月/用户起,提供 GPT-4、DALL-E、Advanced Data Analysis 等高级功能)。
- API 调用按 Token 数量和模型类型计费,DALL-E 生成图片按张数和分辨率计费。
2. Google (模型:Gemini Family – 如 Gemini Pro, Gemini Advanced/Ultra)
- 能力与使用方法:
- 内容与结构:类似于 GPT-4,擅长生成文本内容、提炼要点、规划信息图结构。
- 多模态理解:可以分析包含图文的信息(例如上传现有图表或草图),并基于此进行讨论或提出改进建议。
- 数据分析与图表建议:Gemini Advanced 或通过其 API/Vertex AI 平台,可以处理数据并建议可视化形式。理论上也能生成图表代码(如 Python)。
- 视觉元素生成 (潜在):Google 拥有强大的图像生成模型 Imagen,虽然在消费级 Gemini 中的直接整合用于复杂信息图元素生成尚不明确或不如 DALL-E 在 ChatGPT 中那么直接,但通过 API 或特定工具可能实现。
- 整合 Google Workspace:潜在优势在于未来可能与 Google Sheets (数据处理)、Docs (文案)、Slides (简单布局) 更紧密集成。
- 使用 Gemini 聊天界面进行文本和构思很简单。
- 利用其数据分析或代码生成能力需要一定的技术背景。
- API 或 Vertex AI 平台使用门槛较高。
- Gemini Web/App 界面 (免费版使用 Gemini Pro,订阅版使用 Gemini Advanced)。
- Google AI Studio / Vertex AI Platform (提供 API 和更专业的 MLOps 工具)。
- Gemini 免费版。
- Gemini Advanced 订阅(通常捆绑在 Google One AI Premium 计划中,约 20美元/月)。
- API / Vertex AI 按使用量(字符数、请求数、计算资源等)计费。
3. Microsoft (模型:Copilot – 底层常使用 OpenAI 的 GPT 模型,结合 Bing 搜索和 Microsoft Graph)
- 能力与使用方法:
- 集成体验:Copilot 的主要优势在于深度集成到 Microsoft 365 生态中。
- 内容辅助:在 Word 中生成文案,在 PowerPoint 中生成大纲或简单的设计建议(可能包括基础图表),在 Excel 中分析数据并建议图表(Excel 已有此功能,Copilot 可能增强)。
- 创意与研究:利用 Bing 搜索整合最新信息,辅助构思信息图主题和内容。
- 图像生成:通过 Microsoft Designer 或 Copilot 内的图像创建器(基于 DALL-E)生成单个视觉元素。
- 工作流整合:可以在用户熟悉的应用内提供信息图创作的辅助,减少工具切换。
- 在 M365 应用内使用相对简单直观,门槛较低。
- 独立使用 Copilot 聊天界面也较容易。
- 充分利用需要订阅 Microsoft 365 及 Copilot Pro/商业版。
- 集成在 Windows、Edge、Microsoft 365 应用中。
- 独立的 Copilot Web/App 界面。
- Azure AI Studio / Azure OpenAI Service (面向开发者和企业)。
- 基础版 Copilot 免费。
- Copilot Pro 订阅(约 20美元/月/用户,解锁更多功能和优先访问权)。
- Copilot for Microsoft 365 (面向企业,约 30美元/月/用户,需有 M365 商业版基础订阅)。
- Azure 服务按使用量计费。
4. Anthropic (模型:Claude 3 Family – Haiku, Sonnet, Opus)
- 能力与使用方法:
- 强大的文本处理:Claude 系列以其强大的长文本理解和生成能力著称,非常适合从大量报告或文章中提取关键信息并重写为适合信息图的简洁文案。
- 结构化输出:能较好地按照指定格式(如 Markdown)输出内容,有助于信息图的结构化规划。
- 数据解读与建议:可以分析文本描述的数据或直接输入的数据(在长上下文窗口内),进行总结并提供可视化建议。
- 代码生成:也能生成用于绘制图表的代码(如 Python)。
- 图像能力有限:Claude 3 虽然增加了图像输入能力(可以“看懂”图表),但其原生图像“生成”能力相比 OpenAI/Google 较弱,不直接用于生成视觉元素。
- Web 聊天界面使用简单。
- API 使用需要编程。
- Claude.ai Web 界面。
- API。
- 免费版(有限制)。
- Claude Pro 订阅(约 20美元/月)。
- API 按 Token 数量和模型(Haiku 最便宜,Opus 最贵)计费。
总结与建议
- 没有“一键生成”方案:目前没有任何一家 SOTA LLM 公司能直接、完美地生成“令人惊叹的(Stunning)”信息图。它们都是强大的辅助工具。
- 文本与构思是强项:所有这些模型都能极大地加速信息图的内容创作、结构规划和创意构思过程。
- 数据处理与图表建议:GPT-4 (带 Code Interpreter)、Gemini Advanced 和 Claude 在分析数据、提炼见解和建议图表方面表现不错,甚至能生成基础图表的代码。
- 视觉元素生成:OpenAI (DALL-E) 和 Microsoft (集成 DALL-E) 在生成单个图标、插画方面目前整合得更直接。Google 也有强大能力但整合方式可能不同。
- 易用性:对于非技术用户,通过聊天界面与这些模型交互是最简单的方式。
- 成本:各家都提供免费层级,但要充分利用其高级功能(如最强模型、数据分析、图像生成),通常需要付费订阅或按 API 使用量付费。
- 最终实现:无论使用哪个 LLM 辅助,最终都需要专业的图形设计软件(如 Canva AI、Piktochart AI、Adobe Express、Figma 等,这些工具自身也在集成 AI 功能)来完成布局、配色、字体选择、品牌元素添加以及最终的精修,才能达到“Stunning”的效果。
最佳实践:
建议采用混合方法:
- 使用你偏好的 LLM(如 ChatGPT Plus, Gemini Advanced, Claude Pro)进行头脑风暴、内容生成、结构规划和数据初步分析。
- 如果需要,利用 LLM 的图像生成功能(如 DALL-E)创建一些基础的视觉元素或图标作为素材。
- 将 LLM 生成的文本、数据洞察以及可能的视觉元素导入到专业的信息图设计工具(如 Canva, Piktochart, Visme, Adobe Express 等)中。
- 在设计工具中利用其模板、素材库、布局工具和设计功能,结合 AI 辅助(如果该工具提供),完成最终的视觉设计和排版。
选择哪家公司的模型,取决于你的具体需求、预算、以及你更习惯哪个生态系统(如 Google Workspace 或 Microsoft 365)。对于纯粹的内容和创意生成,各家顶尖模型表现都相当出色,可以尝试后选择最符合你风格的
国内情况
腾讯的可视化产品矩阵
腾讯云图数据可视化平台
腾讯云图数据可视化(Tencent Cloud Visualization)是一站式数据可视化展示平台,专为帮助用户快速通过可视化图表展示大量数据而设计,使用户能低门槛快速打造专业大屏数据展示。
使用方法:
- 采用拖拽式自由布局,全图形化编辑界面
- 不必预先导入数据,用户可以直接将需要呈现的组件拖拽到画布上进行自由配置和布局
- 支持从多种数据源接入数据,包括静态数据、CSV文件、公网数据库、腾讯云数据库和API等
难易程度:
- 操作简单直观,所见即所得的编辑方式
- 精心预设多种行业模板,降低了设计门槛
- 不需要专业的编程或设计知识即可创建专业可视化效果
接口方式:
- 基于Web页面渲染,无需额外安装软件
- 支持公开发布,将大屏URL直接分享给他人浏览
- 支持密码验证和基于HMAC-SHA256 base64加密鉴权的Token验证两种加密方式
成本:
- 搜索结果中未明确提及价格,但作为云服务产品,可能采用按需付费或包月订阅模式
腾讯元宝AI应用
腾讯元宝作为腾讯基于混元大模型推出的AI原生应用,近期升级了多项文档解析和数据可视化能力。
使用方法:
- 支持单文档最长1000万字的超长文处理
- 能够一次性解析最多50个文件(单个文件大小不超过100MB)
- 支持解析多种文件格式,包括pdf、doc、txt、xlsx、pptx
- 基于解析内容,可一键生成柱状图、折线图、饼状图等多种数据图表
难易程度:
- 用户体验友好,只需上传文件或提供URL链接即可获得可视化结果
- 深度阅读模式可提供核心内容概览及模块化解析,生成总结性图表
- 针对财报等专业内容,可根据财报内容生成杜邦分析图等专业图表
接口方式:
- 提供小程序和App两种使用方式
- 支持从微信中直接打开文件进行解析
成本:
- 搜索结果中未明确提及价格,但作为腾讯的消费级应用,可能有免费使用额度
腾讯云BI
腾讯云BI是一个商业智能报表工具,基于大语言模型打造的新一代数据分析引擎。
使用方法:
- 提供从数据源接入、数据建模到数据可视化分析的全流程BI能力
- 通过自然语言对话即可完成数据分析、可视化呈现和数据洞察
难易程度:
- 敏捷自助式设计,使用者仅需通过简单拖拽即可完成复杂的报表开发
- 大幅降低了数据分析门槛,提升数据分析效率
接口方式:
- ChatBI网页交互界面
成本:
- 腾讯云ChatBI目前支持免费体验
阿里云的可视化能力布局
阿里云百炼大模型平台
阿里云百炼是企业级大模型开发平台,提供多种模态的模型服务和应用构建能力。
使用方法:
- 提供丰富多样的模型服务,包括文本、语音、图片等多种模态大模型
- 支持5-10分钟低代码快速构建智能体
- 兼容LlamaIndex等开源框架和OpenAI的Assistant API调用
难易程度:
- 应用构建开放高效,业务落地更轻松
- 提供全链路的模型训练及评估工具
- 包含插件工具、智能体编排组件和精细化运营工具箱等
接口方式:
- 提供实时/Batch调用多种服务计费模式
- 支持在线部署模型按需扩缩容
成本:
- 支持包月或先用后付结算
- 新用户提供千万token免费额度
- 离线调用推理,成本直降50%
阿里云通义千问视觉模型
阿里云通义千问视觉理解模型(Qwen-VL系列)提供强大的视觉理解能力,可用于图像分析和数据可视化。
使用方法:
- 通过API调用模型进行视觉理解和分析
难易程度:
- 需要一定的开发能力来集成和使用API
- 适合开发者和企业用户
接口方式:
- API接口调用
成本:
- Qwen-VL-Plus输入定价为0.0015元/千tokens(降价81%,全网最低价格)
- Qwen-VL-Max输入价格从0.02元/千tokens降至0.003元/千tokens(降幅85%)
- 按照最新价格,一元钱可以最多处理大约600张720P图片,或1700张480P图片
- 通义千问VL-Max-0201计费为0.15元/千Token
- 通义千问VL-Plus计费为0.03元/千Token
字节跳动的可视化技术
豆包视觉理解模型
字节跳动推出的豆包视觉理解模型,在视觉内容分析和可视化方面提供了强大支持。
使用方法:
- 通过API调用模型进行视觉内容理解和分析
难易程度:
- 需要技术背景和开发能力
- 适合企业开发者使用
接口方式:
- API接口调用
成本:
- 每千tokens输入价格为0.003元
- 一元钱可处理284张720P的图片,比行业价格便宜85%
- 据抖音集团副总裁李亮表示,这一定价有"可观的毛利"
ViTamin视觉基础模型
字节跳动推出的ViTamin是专为视觉语言时代设计的视觉基础模型,虽然主要面向AI视觉解析,但也可应用于高级可视化场景。
使用方法:
- 搜索结果中未提供详细信息,但作为基础模型,可能需要二次开发来应用于可视化场景
难易程度:
- 作为基础模型,可能需要较高的技术门槛进行应用开发
接口方式:
- 搜索结果中未明确提及
成本:
- 搜索结果中未明确提及价格
大模型可视化价格战趋势分析
2024年以来,大模型领域掀起了一轮"价格战",各大公司纷纷降低API调用费用:
- 2024年12月,阿里云宣布通义千问视觉理解模型全线降价超80%
- 2024年5月,智谱、字节、阿里云、百度、科大讯飞和腾讯相继宣布降价策略
- 字节跳动豆包视觉理解模型每千tokens输入价格仅为0.003元,比行业价格便宜85%,这一价格竞争趋势对市场产生了积极影响:
- 让更多公司和开发者用上了大模型,实现大模型在中国市场的快速普及
- 降低API调用价格,带动应用生态的兴起,降低创新试错成本
- 促使企业调整战略,回归到大模型用户的角色,避免资源浪费
结论
通过对腾讯、阿里云和字节跳动在信息可视化领域的大模型能力比较,我们可以得出以下结论:
- 产品定位不同:腾讯的产品更倾向于面向普通用户的可视化工具(腾讯云图、腾讯元宝)和企业级BI解决方案(腾讯云BI);阿里云和字节跳动则更聚焦于提供开发者可调用的模型API服务。
- 易用性梯度:腾讯云图和腾讯元宝对非专业用户最友好,采用拖拽式和对话式界面;阿里云百炼提供低代码开发环境,适合有一定技术背景的用户;而通义千问、豆包和ViTamin等模型API则需要较高的技术门槛。
- 价格竞争激烈:大模型API调用价格呈下降趋势,阿里和字节在视觉模型方面竞争尤为激烈,这有利于降低应用开发和使用成本。
- 技术路线多元:不同公司采用不同技术路线,腾讯强调混元大模型和多模态交互,阿里强调通义千问视觉理解能力,字节则推出ViTamin等专用视觉基础模型。
总体而言,大模型驱动的信息可视化工具正在走向普及化和平民化,价格门槛不断降低,用户体验不断优化,为各行业数据可视化和决策分析提供了强大支持。企业和个人用户可根据自身技术能力和应用需求,选择适合的产品和服务。

留下评论