
启幕——征服智力游戏的巅峰
Alpha传奇的序幕,在一个19×19的棋盘上拉开。围棋,这个起源于数千年前的东方智力游戏,成为了检验DeepMind宏大理想的第一个,也是最完美的试炼场。要理解AlphaGo的胜利为何如此震撼,首先必须理解围棋为何被视为AI领域一座难以逾越的高山。
1.为什么是围棋?AI的“宏大挑战”
数十年间,围棋一直被视为人工智能领域的“宏大挑战”(grand challenge)。当计算机在国际象棋领域凭借“深蓝”(Deep Blue)战胜世界冠军加里·卡斯帕罗夫(Garry Kasparov)后,围棋依然是AI难以企及的圣杯。其难度根植于两个核心特性:
首先是其无法估量的复杂性。围棋的棋盘状态空间极其浩瀚,可能的变化数量达到了惊人的10170,这个数字远超宇宙中已知的原子总数。相比之下,国际象棋的复杂度虽然也很高,但仍处于可计算的范畴内。这种天文数字般的可能性,使得任何试图通过“暴力穷举”搜索所有可能性的方法都注定失败。
其次是其评估函数的模糊性。与国际象棋中每个棋子都有明确的价值不同,围棋中一颗棋子的价值是动态且高度依赖于全局形势的。评估一个围棋盘面的优劣极其困难,顶尖棋手往往依赖一种难以言说的“棋感”或“直觉”来做出判断,而这种能力曾被认为是人类智慧独有的标志。
正因如此,围棋成为了测试通用学习系统的理想平台。它简单的规则背后蕴含着无穷的策略深度,为一种不依赖人类硬编码规则、能够自主学习模式和策略的AI提供了完美的成长环境。DeepMind的目标从来就不是仅仅制造一个围棋机器,而是要通过征服这个终极挑战,来锻造和验证一种更通用的智能形式。
2. AlphaGo登场:一种新心智的诞生
为了应对围棋的挑战,DeepMind创造了AlphaGo,一个并非单一算法,而是由多个核心部分协同工作的复杂系统。其创新的混合架构,为AI领域开辟了新的道路:
- 策略网络(Policy Network):这是AlphaGo学习的起点。研究团队首先使用一个包含约3000万步人类专家棋局的数据库对其进行训练,这被称为监督学习(Supervised Learning)。通过模仿顶尖棋手的下法,策略网络学会了判断在特定盘面下,哪些落子点是值得考虑的。这为AlphaGo打下了坚实的“人类知识”基础。
- 强化学习(Reinforcement Learning):在掌握了人类棋谱的基础后,AlphaGo开始进入自我进化的阶段。它通过与自身的无数个克隆版本进行对弈,从零开始学习。每局棋的胜负都成为一个反馈信号,胜利的走法会被“强化”,失败的则被“削弱”。通过数百万次的自我对弈,AlphaGo的RL策略网络逐渐超越了其最初模仿的人类水平,发现了全新的策略。
- 价值网络(Value Network):与策略网络预测“下一步该怎么走”不同,价值网络的目标是评估整个棋盘的局势,预测“从当前局面出发,最终获胜的概率是多少”。这个全局性的判断力至关重要,它让AlphaGo能够进行长远的战略规划,而不是只关注眼前的得失。
- 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS):MCTS是整个系统的大脑和决策中枢。它像一个聪明的探索者,在庞大的可能性之树中进行搜索。策略网络负责为MCTS指明哪些分支(即可能的落子)更有探索价值,从而大大减少了搜索的广度。而价值网络则在探索到一定深度时,快速评估当前局面的胜率,避免了无休止的向下推演。这种策略网络与价值网络双重引导的MCTS,是AlphaGo能够高效、智能地在天文数字般的可能性中找到最佳路径的核心所在。
这个系统的成功,标志着一种全新AI范式的确立:通过深度学习赋予机器强大的模式识别和直觉能力,再通过强化学习进行自我完善,最后由高效的搜索算法将这些能力转化为精准的决策。这套方法论不仅为征服围棋铺平了道路,也为后续所有Alpha家族成员的诞生奠定了基石。
3.世纪之战:AlphaGo对决李世石
2016年3月,全世界的目光聚焦于韩国首尔。一场被誉为“世纪之战”的五番棋对决在此上演,对阵双方是DeepMind的AI程序AlphaGo与拥有18个世界冠军头衔的传奇棋手李世石(Lee Sedol)。这场比赛吸引了全球超过2亿人观看9,其重要性被普遍认为堪比1997年IBM深蓝与卡斯帕罗夫的国际象棋对决。
大多数专家曾预测,AI要战胜围棋世界冠军,至少还需要五到十年。然而,AlphaGo的表现震惊了世界。最终,它以4比1的总比分战胜了李世石22。这位人类顶尖棋手在赛后坦言感到“无力”和“震惊”。为了表彰其卓越的棋力,韩国棋院甚至授予了AlphaGo荣誉职业九段的称号——这是围棋界的最高等级。
这场对决的戏剧性不仅在于最终的比分,更在于棋盘上那些闪耀着智慧火花的瞬间,它们深刻地揭示了AI与人类智能的异同。
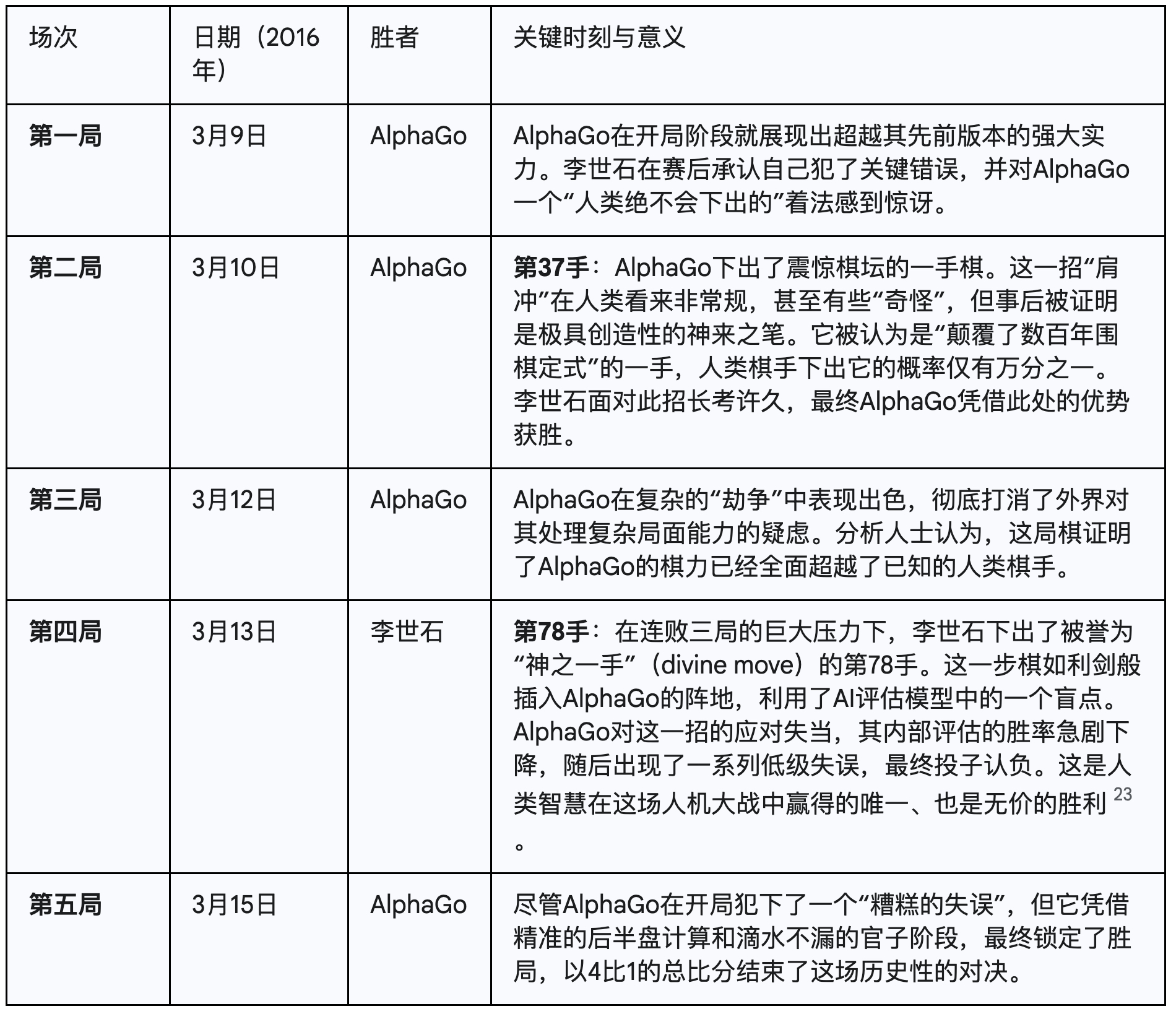
这场比赛充分展现了AI的“异类”创造力。第二局的第37手棋表明,AI不只是在模仿和计算,它能够通过探索人类思维从未触及的可能性空间,创造出全新的知识。然而,第四局第78手棋也揭示了这种基于概率模型的AI的潜在弱点:它的“世界观”是由其学习数据和自我博弈经验构建的,对于那些概率极低、出乎意料的“黑天鹅”事件,它可能会反应失常。这暗示了人类的创造性直觉与AI强大的计算能力之间存在着一种深刻的互补关系。
4.赛后余波:一场范式转移
AlphaGo的胜利标志着一个时代的终结。正如“深蓝”的开发者之一穆雷·坎贝尔(Murray Campbell)所言,“棋盘游戏(作为AI挑战)的时代或多或少已经结束了,是时候向前看了”。围棋,这个人类智慧最后的堡垒,已被AI攻克。
然而,对于DeepMind而言,这仅仅是开始。这场胜利的意义远超围棋本身。它不仅在围棋界掀起了一场革命,顶尖棋手们开始研究AlphaGo的棋谱,探索围棋的新思路,更重要的是,它向世界证明了DeepMind核心方法论的强大威力。通过将一个复杂问题(围棋)形式化为一个巨大的搜索空间,并利用深度强化学习来寻找最优解,AI能够达到甚至超越人类的顶尖水平。这次成功为DeepMind赢得了巨大的声誉和信心,使其能够将目光从游戏投向更广阔、更具现实意义的领域。AlphaGo完成了它的历史使命,成为了通往通用人工智能道路上一块坚实的垫脚石,为后续所有Alpha成员的诞生铺平了道路。

留下评论