
第一章:信息检索的历史根基(续)
学科的正式化与早期实验:布尔逻辑与SMART系统
“信息检索”一词最早由卡尔文·穆尔斯在1950年3月的一次会议上提出,此举确立了这个领域的身份。最早的计算机化搜索系统则出现于20世纪40年代后期,其灵感来源于20世纪上半叶的开创性创新。
将布尔逻辑引入信息检索标志着从浏览到系统化搜索的革命性转变。乔治·布尔1854年的著作《思想法则研究》提供了数学基础,但实际应用直到20世纪中期才出现。(这位青史留名的布尔应该无论如何都想不到,他的一位叫杰夫·辛顿的重外孙在21世纪一举揭开了人类智力奥秘!)1952年,陶布等人提出的Uniterm系统,通过关键词列表对条目进行索引,这在当时是对传统分层分类的激进突破。
20世纪60年代,杰拉德·萨尔顿及其康奈尔大学的同事创建了SMART信息检索系统,这是该领域的一个里程碑。它为现代信息检索技术和关键概念奠定了基础,包括词-文档矩阵、向量空间模型(斯威策于1963年首次提出,萨尔顿于1975年进一步完善)、相关性反馈(罗基奥于1965年引入)和罗基奥分类。SMART系统在实验室条件下评估了各种搜索选项,处理自然语言形式的摘要。
排序检索,即根据相关性得分对文档进行排序,由卢恩于1957年提出,并经实验证明优于布尔搜索。20世纪70年代,将卢恩的词频与斯帕克·琼斯的反文档频率相结合的tf-idf(词频-逆文档频率)加权方案被广泛采用 1。罗伯逊在1977年定义了概率排序原则,为优化文档排序提供了形式化基础。信息检索从布尔检索(精确匹配)到排序检索的演变,以及tf-idf和相关性反馈等概念的发展,标志着“相关性”定义和计算方式的关键转变。早期系统是二元的(匹配/不匹配)。排序算法的引入承认了并非所有“匹配”都同样有用,并且某些部分匹配可能比精确但不太重要的匹配更相关。这为后来主导该领域的概率和统计方法奠定了基础。
IBM的STAIRS(存储与信息检索系统)和美国国家医学图书馆的MEDLARS是首批大规模通用信息检索系统,对商业和医学领域产生了影响。克莱弗登领导的克兰菲尔德测试(1957-1966年)是信息检索系统的首次全面评估,确立了评估方法和度量标准,并揭示了查全率和查准率之间的反向关系。
早期挑战与局限性:查全率、查准率与语义鸿沟
尽管取得了显著进步,但信息检索从未完美无缺。早期手工索引系统存在根本性的可扩展性限制,因为手工过程无法跟上已发表文献的指数增长,且质量索引所需的人类专业知识成为瓶颈。
自然语言固有的模糊性使得准确解释用户查询和捕捉内容深层含义变得困难,导致了“语义鸿沟”问题。这种挑战不仅仅是一个限制,而是一个持续存在的问题,它推动了信息检索领域数十年的研究,从统计方法到自然语言处理,再到现在的深度学习。类似的问题也会影响图像和视频等非文本对象的索引和评估。
确定相关性是主观的,并根据用户语境和意图而异,通用标准可能无法反映特定用户需求。信息和用户表达缺乏清晰度是信息检索成功的主要障碍。信息检索领域的一个持续存在的挑战是查全率(召回所有相关文档)和查准率(只召回相关文档)之间的权衡。克兰菲尔德测试明确了这一基本概念,并表明优化其中一个指标通常会以牺牲另一个为代价。例如,MEDLARS的评估结果显示,其总体查准率仅为50.4%,表明近一半的检索结果是不相关的。
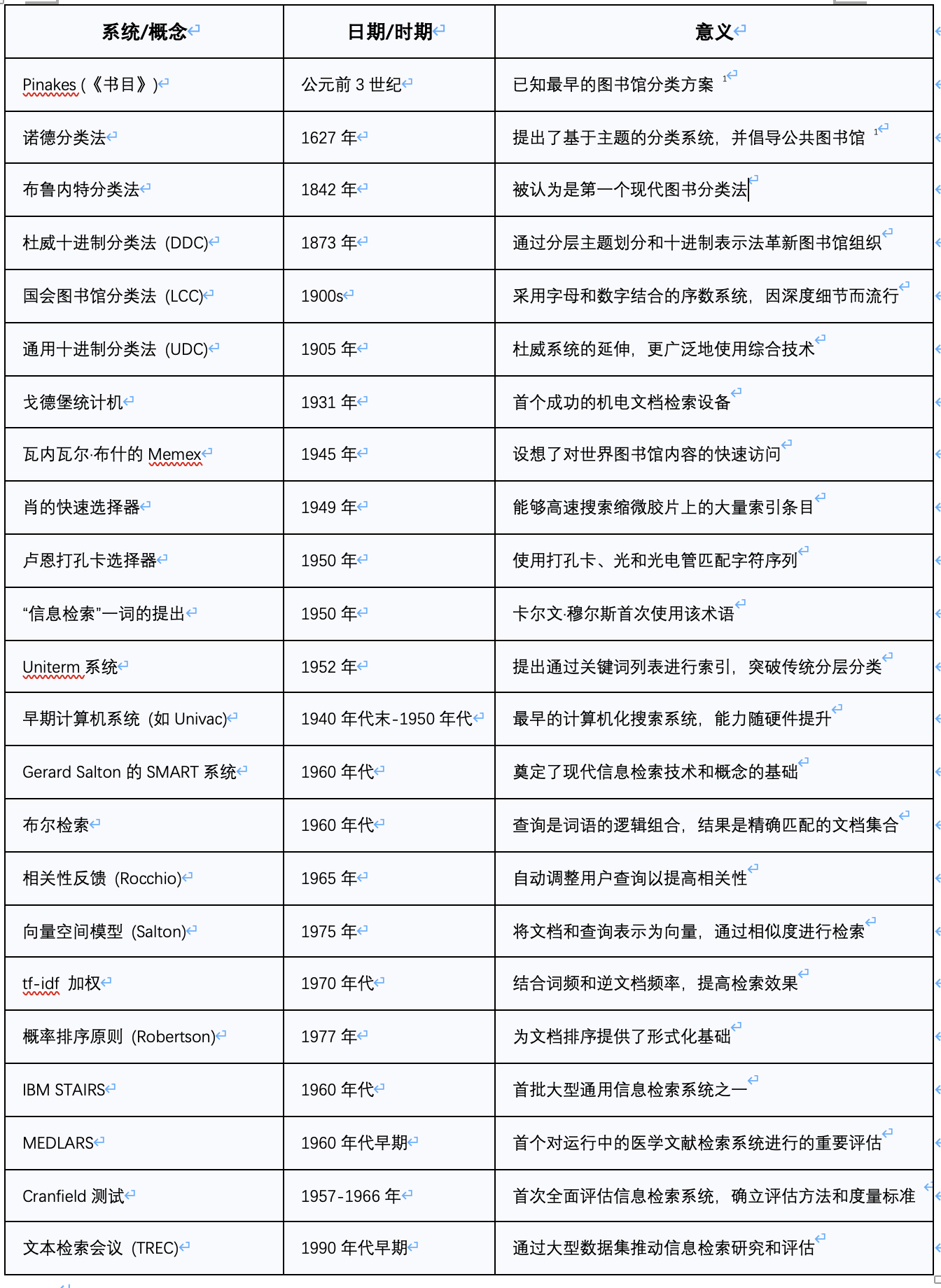
表1:信息检索历史上的关键里程碑

留下评论