
第二章:现代信息检索的变革:从关键词到语义理解(续)
向语义搜索的过渡:理解意图与语境
信息检索已从简单的关键词匹配迅速发展到注重语境的系统,以提高准确性、相关性和用户交互。最初,搜索技术严重依赖关键词匹配和TF-IDF等技术来组织、搜索和排名信息。
语义搜索的出现旨在解决词汇(基于关键词)搜索的局限性,后者在处理歧义和语境细微差别方面存在困难。它利用自然语言处理(NLP)和机器学习(ML)来分析词语和概念之间的关系,理解用户意图和语境,而不仅仅是字面上的关键词匹配 1。这使得系统能够解释同义词并识别词语之间的关系 1。从词汇搜索到语义搜索的转变不仅仅是技术升级,它反映了对用户行为更深层次的理解。用户不仅仅是输入词语,他们有潜在的意图和语境。语义搜索试图回答查询背后“为什么”的问题,而不仅仅是“什么”。这意味着从找到包含特定词语的文档,转向提供解决潜在需求的答案,即使措辞模糊。这直接弥合了第一章中指出的“语义鸿沟”。
Google向语义搜索的转变包括一系列关键创新:2010年收购语义数据库Freebase,2012年引入知识图谱(一种映射实体之间关系的图索引),2013年推出蜂鸟(Hummingbird)算法更新(旨在更好地解释复杂查询和搜索意图),以及2015年正式通过Rankbrain引入机器学习(使用向量空间分析来理解主题邻近性)。
NLP的演进,从早期的基于规则的系统(如20世纪60年代的ELIZA和SHRDLU)到20世纪70-80年代向统计模型的转变,以及20世纪90年代隐马尔可夫模型(HMMs)的引入,再到2010年代深度学习的突破,极大地重塑了搜索领域。Google于2018年推出的BERT(双向编码器表示变换器)通过实现对介词和上下文的更好理解,影响了10%的搜索查询,显著推动了NLP的发展。BERT旨在为搜索添加语境,并通过理解词语在句子中的位置和与其他词语的关系来“连接点”,从而提高了复杂和长尾查询的相关性,超越了字面关键词匹配的局限性。Google于2021年推出的多任务统一模型(MUM)进一步增强了对各种内容形式(文本、视频、音频、图像)的语义理解。
现代信息检索系统的核心组件解析
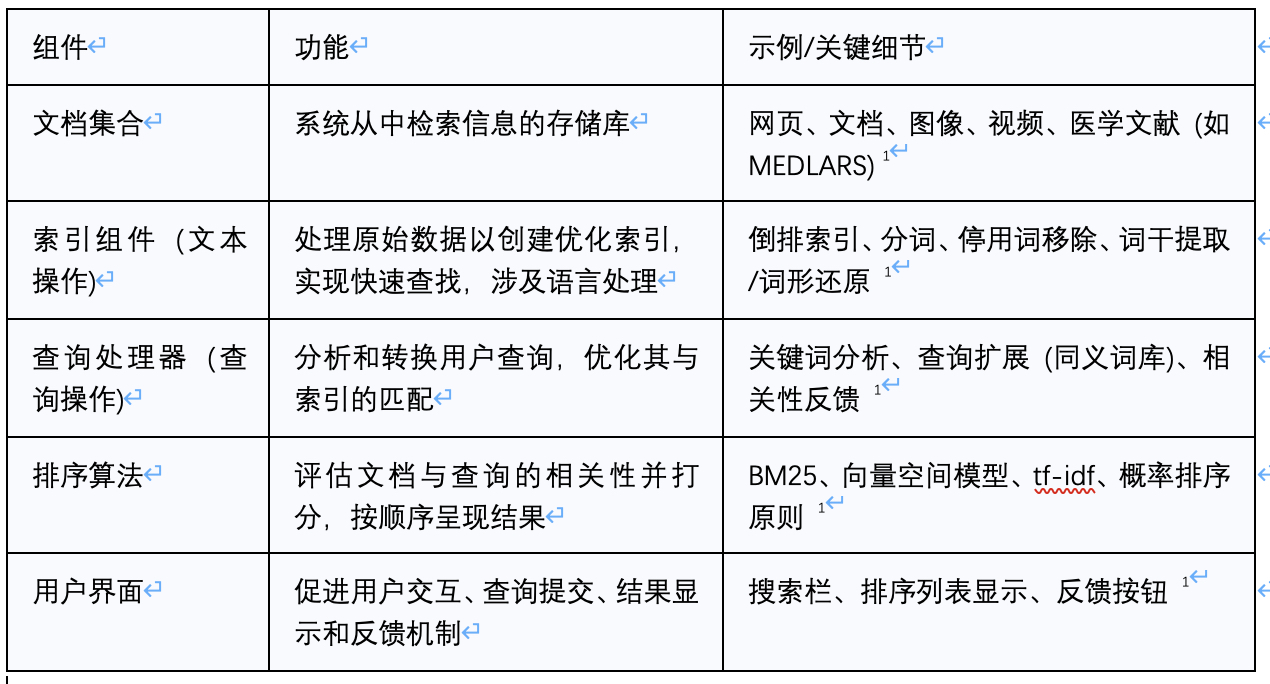
一个典型的信息检索系统由几个关键组件构成:
- 文档集合: 这是系统从中检索信息的文档或数据集的存储库,例如网页、文档、图像、视频或医学文献。
- 索引组件: 该组件负责处理原始数据以创建优化索引,从而实现快速查找。它涉及语言处理步骤,如分词(将文本分解为单个词语)、停用词移除(删除“the”等常见、低价值的词语)以及词干提取或词形还原(将词语还原为其基本形式)。倒排索引是此处常用的数据结构。
- 查询处理器: 查询处理器分析用户查询和关键词,为与索引实体匹配做准备。它还可以通过查询扩展(例如,使用同义词库)或相关性反馈来转换查询,以提高检索效果。
- 排序算法: 这些算法根据文档与查询的相关性为其分配分数,并将结果以排序列表的形式呈现给用户。常见的算法包括BM25、向量空间模型和tf-idf等。
- 用户界面(UI): 用户界面是用户与系统交互的显示界面,用于提交查询并查看结果。它还可以允许用户提供对检索文档相关性的反馈,以改进未来的检索。
这些核心组件的列表不仅仅是一个清单,它展示了一个相互依赖的系统。每个组件都依赖于其他组件才能有效运行。例如,“索引组件”的质量直接影响“查询处理器”的效率和“排序算法”的准确性。这突出表明,一个领域的改进往往需要或促使其他领域的改进,从而导致系统整体的演进,而非孤立的进步。
表2:信息检索系统的核心组件

留下评论