创新溯源——OpenClaw的技术突破与开发者基因
引言:他山之石,可以攻玉
OpenClaw的成功,表面上看是一个"胶水项目"的意外走红,但深入剖析会发现,这背后是对现有技术的深刻理解、对用户需求的精准把握,以及创始人个人特质与时代机遇的完美契合。正如《诗经》所言"他山之石,可以攻玉",OpenClaw并未创造全新的AI模型或算法,而是将散落各处的技术"宝石"巧妙打磨、精心镶嵌,最终铸成了一件令人惊艳的"工艺品"。
要理解OpenClaw的创新,我们需要回答三个问题:它在技术架构上做了哪些关键突破?为什么是彼得·斯坦伯格(Peter Steinberger)这个人能做出这样的产品?以及,这些创新对AI生态有何深远意义?这三个问题环环相扣,共同揭示了一个现象级产品诞生的必然性与偶然性。
三大架构创新:打破常规的设计哲学
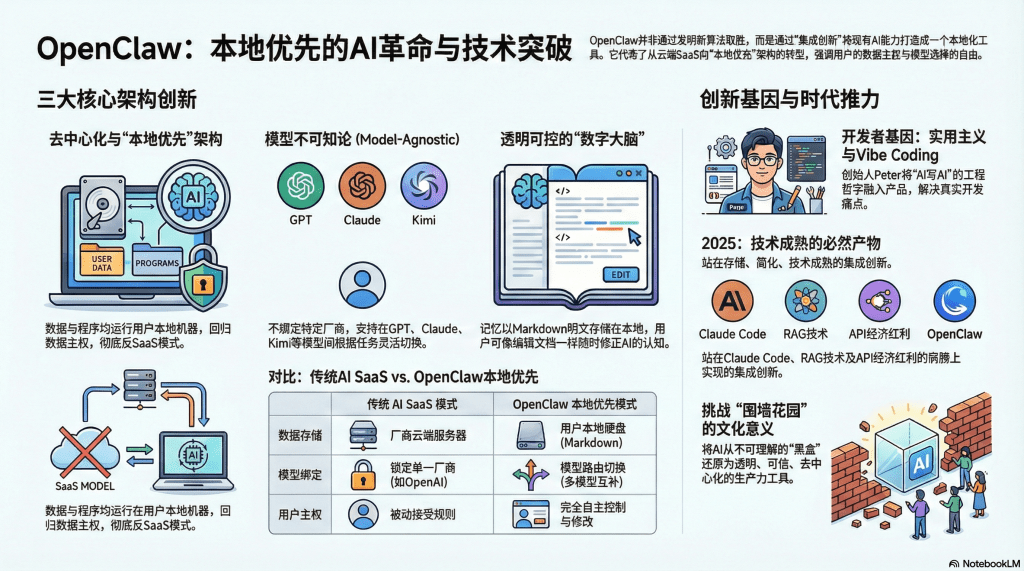
OpenClaw的技术架构并不复杂,甚至可以说是"简陋"的——它没有自己训练的模型,没有独创的算法,大部分代码都是调用现成的API和开源库。但正是这种"拿来主义"式的工程哲学,反而成就了它的独特性。其核心创新可以归纳为三个维度:去中心化设计、模型不可知论和透明记忆系统。
去中心化设计:"你的助手,你的机器,你的规则"
OpenClaw最鲜明的标签是"反SaaS"(Software as a Service,软件即服务)。在云计算盛行的时代,几乎所有AI产品都采用SaaS模式:用户通过浏览器访问厂商的服务器,数据存储在云端,功能更新由厂商控制。这种模式对厂商有利——便于维护、易于收费、掌控用户数据——但对用户来说,意味着完全的依赖和潜在的风险。
OpenClaw则反其道而行之,采用了"本地优先"(Local-First)的架构理念。它的核心是一个"网关"(Gateway)程序,通常部署在用户自己的机器上——可以是一台Mac Mini、一台Linux服务器,甚至是闲置的笔记本电脑。这个网关负责协调多个即时通讯平台(WhatsApp、Telegram、Slack等)的消息路由,并通过"节点"(Nodes)在不同设备上执行具体任务。
这种设计带来的最大好处是数据主权的回归。用户的对话记录、记忆文件、配置信息全部存储在本地硬盘上,不会被上传到某个公司的云端服务器。用户可以随时查看、修改、备份甚至删除这些数据,拥有完全的控制权。这在隐私意识日益觉醒的今天,具有强大的吸引力。
用一个类比来说明:传统SaaS模式像是租房——你住在别人的房子里,房东可以随时涨房租、修改规则,甚至收回房子;而OpenClaw的本地部署模式则像是自建房——虽然需要自己维护,但房子是你的,任何人无权干涉你如何使用。
当然,这种设计也有代价。本地部署意味着用户需要具备一定的技术能力,需要自己解决网络配置、依赖安装等问题。但对于愿意为自由付出学习成本的用户来说,这是一个值得的交换。更重要的是,这种架构为去中心化AI应用打开了一扇门——它证明了,AI不一定要被大公司垄断,个人也可以拥有自己的智能体。
模型不可知论:从"忠诚"到"务实"的转变
OpenClaw的第二个关键创新是"模型不可知"(Model-Agnostic)架构。这意味着它不绑定任何特定的大语言模型,而是可以根据任务需求、成本考量或可用性,灵活切换不同的模型。
在OpenClaw的配置文件中,用户可以设置"模型路由"规则:简单的任务交给便宜快速的模型(如Claude Haiku或国产的Kimi K2.5),复杂的推理任务交给顶级模型(如Claude Opus或GPT-4.5),代码编写则可能选择专门优化过的Mistral或DeepSeek。系统还内置了故障转移机制——如果主力模型的API因为配额耗尽或网络问题而失败,会自动切换到备用模型,确保服务不中断。
这种设计看似简单,实则深刻。在AI行业,大多数产品都会选择"站队"——要么是OpenAI阵营,要么是Anthropic阵营,要么是Google阵营。这种忠诚往往是商业合作的结果,但对用户来说却意味着被锁定。一旦某个模型厂商提价、降级服务或关闭API,依赖该模型的应用就会陷入困境。
OpenClaw打破了这种依赖关系。它将模型视为可替换的"零部件",而非不可或缺的"核心"。这种务实的态度赋予了用户前所未有的自由:你可以根据实际效果选择最合适的模型,可以在多个模型间分散风险,可以利用不同模型的优势互补——比如用Claude做文本生成,用GPT做逻辑推理,用Kimi做中文理解。
更进一步说,这种模型不可知论挑战了AI大厂试图建立的"护城河"。大厂希望通过独占的模型能力来锁定用户,但OpenClaw证明了,只要有足够好的工程化设计,不同模型之间的差异可以被抹平。这对于打破AI领域的垄断趋势,具有重要的战略意义。
从技术实现上看,这种灵活性依赖于一套标准化的接口抽象。OpenClaw定义了一组通用的API格式,不同模型的调用被封装成统一的函数。当需要切换模型时,只需修改配置文件中的几行参数,而不需要重写代码。这种"面向接口编程"的思想,在软件工程中早已是常识,但在AI应用领域却长期被忽视。OpenClaw的成功,再次印证了工程化设计的价值。
透明记忆系统:让AI的"大脑"可见可控
OpenClaw的第三个核心创新是它的记忆系统——一个完全透明、用户可控的"数字大脑"。与商业AI助手将记忆藏在服务器黑盒中不同,OpenClaw将所有记忆存储为本地的Markdown文本文件,用户可以像编辑Word文档一样,随时查看、修改AI对自己的"认知"。
这套记忆系统采用三层架构:
- 身份记忆(Identity.md):记录用户的基本信息、性格特征、沟通偏好等。例如"用户是社会学研究者,偏好简洁的语言,不喜欢过多的技术术语"。
- 工作日记(Daily Logs):每天生成一个以日期命名的文件(如2026-02-06.md),记录当天完成的任务、遇到的问题、解决方案等。这就像AI在写日记,方便未来回溯。
- 常识库(Memory.md):积累长期有效的知识和规则,如"用户的博客使用Hugo框架部署在Vercel上""用户习惯将文献笔记存放在/Documents/Research目录"。
为了让这些记忆能够被高效利用,OpenClaw采用了一套"混合检索"策略。它将Markdown文件切分成约400个Token的小块(Block),相邻块之间保留80个Token的重叠以保持语义连贯,然后提取每个块的语义向量(Embedding)和关键词,存入本地的SQLite数据库。
当用户提问时,系统会同时进行两种检索:
- 语义匹配(70%权重):理解问题的深层含义,找到语义相似的记忆片段。比如问"上次那个菜怎么做",能联想到之前提到的"寿喜烧"。
- 关键词匹配(30%权重):精准定位包含特定术语的记忆。比如搜索"SSH密钥路径",会直接找到包含这个关键词的配置信息。
这种混合策略既保证了检索的灵活性(懂你的意图),又确保了准确性(不会遗漏关键细节)。对于社会科学研究者来说,这种设计尤其重要——他们既需要发散性的概念关联(如福柯的权力理论与当代监控社会的联系),也需要精确的文献定位(如某个具体的统计数据或法条原文)。
更令人称道的是,这种透明性带来了一种独特的信任感。用户不必担心AI会"记错"或"记偏"——如果发现记忆有误,直接打开对应的Markdown文件修改即可。这种"可编辑的记忆",赋予了用户对AI认知的塑造权,从根本上改变了人机关系:AI不再是神秘的黑盒,而是透明的工具;用户不再是被动的接受者,而是主动的塑造者。
创新者的画像:彼得·斯坦伯格何许人也?
要理解OpenClaw为何是这个样子,必须了解它的创造者。彼得·斯坦伯格并非AI领域的学术大牛,也不是互联网巨头的高管,而是一位成功的独立开发者,拥有典型的欧洲技术理想主义者特质。
斯坦伯格最为人知的身份是PSPDFKit的创始人——这是一家专注于PDF技术的公司,为Adobe、Dropbox等知名企业提供PDF渲染和编辑的SDK(软件开发工具包)。这段创业经历塑造了他的两个核心能力:工程化思维和对用户痛点的敏感。
PDF处理是一个看似简单、实则复杂的领域。要处理各种奇怪的文件格式、适配不同的操作系统、优化渲染性能,需要扎实的工程功底和对细节的极致追求。斯坦伯格在这个领域耕耘多年,培养出了一种"用最少的代码解决最多的问题"的实用主义哲学。OpenClaw的架构充分体现了这一点——它没有追求技术的炫酷,而是专注于用现成的工具(Claude API、Markdown、SQLite)解决实际问题(记忆、主动性、多平台)。
更独特的是,斯坦伯格是"Vibe Coding"理念的实践者和传播者。所谓"Vibe Coding",是指完全依赖AI来编写代码,开发者只需描述需求、审查结果,而不必亲自敲击键盘。这种开发方式在传统程序员看来近乎"异端",但斯坦伯格却用实际行动证明了它的可行性——OpenClaw的大部分代码都是由Claude生成的,他本人主要负责架构设计和质量把控。
这种开发方式不仅提高了效率(据称OpenClaw的核心功能在一个周末就基本完成),更重要的是,它让斯坦伯格成为了OpenClaw的第一个深度用户。他在用AI写AI的过程中,深刻体验到了现有工具的不足——对话会失忆、需要重复交代背景、无法主动提醒——这些痛点直接催生了OpenClaw的核心功能。可以说,OpenClaw是"自举"(Bootstrap)出来的产品:用AI开发的AI工具,专门用来改善AI开发体验。
从个人特质上看,斯坦伯格还有一个鲜明特点:对数据主权的执着。作为奥地利人,他深受欧洲GDPR(通用数据保护条例)文化的熏陶,对隐私保护有着近乎本能的重视。这解释了为什么OpenClaw坚持本地部署、为什么记忆文件是明文可读的、为什么所有数据都不离开用户的硬盘。这不仅是技术选择,更是价值观的体现。
有趣的是,OpenClaw的命名历程也反映了斯坦伯格的个性。最初的名字"Clawd"是对Anthropic旗舰模型"Claude"的致敬,也隐含了"爪子"(Claw)的意象——暗示AI能够抓取和操作数字对象。当Anthropic以商标侵权为由要求改名后,他将项目更名为"Moltbot"(蜕皮机器人),借用甲壳类动物蜕壳成长的隐喻,还在社区掀起了一波龙虾文化(Lobster Meme)的热潮。最终定名"OpenClaw",既强调了开源(Open)属性,又保留了"抓取"(Claw)的功能寓意。这种幽默感和文化创造力,让OpenClaw不仅是一个技术产品,更成为了一种亚文化符号。
时代的必然性:站在2025年末的技术节点
如果说斯坦伯格的个人特质是OpenClaw成功的"人和",那么技术积累的成熟则是"天时"。OpenClaw并非凭空出现,而是站在一系列前驱产品和成熟技术的肩膀上。
Claude Code的铺垫:Anthropic在2025年中推出的Claude Code,是第一个具备"计算机操作"能力的AI助手。它可以控制鼠标键盘、读取屏幕内容、执行Shell命令。虽然Claude Code主要面向企业用户且价格昂贵,但它验证了"AI操作电脑"这条技术路径的可行性。OpenClaw的很多架构设计(如如何处理上下文压缩、如何安全地执行系统命令)都直接借鉴了Claude Code的思路。可以说,没有Claude Code的探索,OpenClaw很难在如此短的时间内完成开发。
RAG技术的成熟:检索增强生成(Retrieval-Augmented Generation)在2024-2025年间从学术论文走向了工程实践。Pinecone、Weaviate等向量数据库的普及,LangChain、LlamaIndex等开源框架的成熟,使得构建记忆系统的门槛大幅降低。OpenClaw没有重新发明轮子,而是直接采用了行业标准的技术栈——这正是"站在巨人肩膀上"的典范。
开源文化的繁荣:GitHub、npm(Node.js包管理器)、Docker等开源基础设施已经极度成熟。一个开发者可以轻松调用数千个开源库,可以通过Docker实现"一键部署",可以利用GitHub Actions实现自动化测试。OpenClaw的代码中,83.5%是TypeScript,大量使用了Node.js生态中的成熟组件。这种"组装式开发"降低了创新的成本,让个人开发者也能做出复杂的系统。
API经济的成熟:Claude、GPT等大模型的API已经相对稳定且价格可承受。一个普通用户用每月20美元的订阅费用,就能获得足够的调用额度来运行一个24小时在线的智能体。这种成本的降低,使得"全天候AI助手"从奢侈品变成了日用品。OpenClaw的成功,某种程度上是"API经济红利"的释放。
同时,2025年末也是一个特殊的心理节点。经过几年的AI热潮,用户已经从最初的新鲜感中走出来,开始追问:"AI到底能为我做什么?"市场上充斥着各种"套壳"产品——换个界面、换个提示词就敢称自己是创新——用户对这种"换汤不换药"的做法已经疲惫。OpenClaw的出现,恰好满足了人们对"真正有用的AI"的渴望。它不是又一个聊天机器人,而是真正能够介入工作流、提高生产力的工具。这种"实用主义回归"的趋势,是OpenClaw爆发的社会心理基础。
意义的多重维度:技术、商业与文化
OpenClaw的创新,不能仅从技术层面评判,它在商业模式和文化价值上同样具有深远意义。
技术层面:证明"胶水代码"的价值
在技术圈有一种偏见,认为只有底层创新(如新算法、新架构)才值得尊重,而"胶水代码"(Glue Code)——即将现有组件拼接在一起的工程工作——是低层次的。OpenClaw用实际效果反驳了这种偏见。它没有发明新模型,没有提出新理论,但它解决了大模型无法解决的问题:如何让AI拥有长期记忆?如何让AI主动行动?如何让AI融入日常工作流?
这种"集成创新"的价值,恰恰在于它站在用户视角而非技术视角。用户不关心你用的是什么算法,他们只关心能否解决问题、是否好用。OpenClaw的成功提醒我们,在AI应用领域,工程化能力可能比模型能力更重要。一个二流的模型加上一流的工程设计,可以打败一流的模型加上二流的产品体验。
商业层面:挑战大厂的"围墙花园"
OpenAI、Anthropic、Google等大厂都试图建立自己的"生态闭环":用户只能用他们的模型、他们的API、他们的开发工具,数据锁定在他们的服务器上。这种"围墙花园"(Walled Garden)策略虽然对厂商有利,但限制了用户的自由,也抑制了生态的多样性。
OpenClaw的模型不可知论和本地部署模式,从根本上挑战了这种垄断趋势。它证明了,用户不必被任何一家厂商绑架,可以根据自己的需求自由选择最合适的工具。这对于推动AI行业的良性竞争、防止技术垄断,具有重要意义。
从更宏观的角度看,OpenClaw代表了一种"去中心化AI"的可能性。如果说传统AI是"中央集权"的——所有能力都集中在大公司手中,那么OpenClaw则暗示了一种"联邦制"的未来——个人可以拥有自己的AI,可以选择与哪个模型厂商合作,可以随时切换或组合不同的服务。这种架构上的去中心化,与区块链、联邦学习等技术趋势遥相呼应,预示着未来AI生态可能的演化方向。
文化层面:从"黑盒"到"透明"的信任重建
AI技术的一个长期困境是"黑盒问题"——用户不知道AI是如何做出决策的,不知道它记住了什么、遗忘了什么。这种不透明性导致了信任缺失,也限制了AI在高风险场景(如医疗、法律)的应用。
OpenClaw的透明记忆系统,是对这个问题的一种回答。它将AI的"思考过程"可视化,将记忆文件暴露给用户,赋予用户编辑权。这种设计虽然简单,却具有深刻的文化意义:它将AI从不可理解的"神谕",还原为可理解、可控制的"工具"。
这对于图书馆和学术研究领域尤其重要。研究者需要确保AI引用的文献是准确的、分析的逻辑是严谨的。如果AI的推理过程是黑盒,研究者就无法验证其可靠性。而OpenClaw式的透明设计,让研究者可以追溯AI的每一步思考,可以修正错误的假设,可以将AI作为可信赖的研究助手。这种"白盒化"趋势,可能成为未来学术AI工具的必备特性。
结语:九层之台,起于累土
《老子》有云:"九层之台,起于累土。"OpenClaw看似横空出世,实则是无数技术积累、无数创新尝试的集大成者。它的成功不是因为发明了某种颠覆性技术,而是因为在恰当的时机,用恰当的方式,将散落的技术碎片拼成了一幅完整的图景。
彼得·斯坦伯格的个人特质——工程化思维、实用主义哲学、对隐私的执着——与2025年末的技术成熟度——大模型API、RAG技术、开源生态——在OpenClaw这个产品上完美汇聚。它既是个人天才的闪光,也是时代必然的产物。
对于AI行业来说,OpenClaw最重要的启示或许是:创新不一定需要从零开始,重新组合现有元素同样可以产生巨大价值。在追逐AGI(通用人工智能)的宏大叙事之外,还有另一条路径:通过精巧的工程设计,让现有的AI更好用、更可靠、更符合人性。这条路或许不够性感,但对于普通用户来说,它可能更加实际、更加重要。
在下一篇文章中,我们将从技术的云端回到社会的现实,探讨OpenClaw评价反转的全过程:为什么它在短短几天内从"全网吹爆"走向"质疑四起"?这些质疑是否合理?我们又该如何理性看待一个充满争议的创新产品?
【下期预告】狂欢与审慎——从全网吹爆到质疑四起的反转逻辑。我们将深入分析OpenClaw面临的安全隐患、成本失控、信任危机等问题,探讨"极客玩具"与"生产级产品"之间的鸿沟,以及如何通过物理隔离、云端沙盒等方案破解这些难题。

留下评论