数字记忆——让AI拥有连续的"过去"
引言:白纸黑字,了然于胸
明代学者陈继儒在《小窗幽记》中写道:"事能知足心常惬,人到无求品自高。"虽然这句话讲的是人生哲理,但其中"知足"二字,用来形容OpenClaw的记忆设计颇有深意——它没有追求复杂的神经网络记忆模型,而是回归最朴素的方式:白纸黑字,明明白白地将记忆写成文件。这种"返璞归真"的设计哲学,反而成就了它最具创新性的特质——透明、可控、可审计的数字记忆。
在人工智能的历史长河中,"记忆"一直是一个核心挑战。从早期的专家系统到现代的大语言模型,如何让AI记住用户的信息、保持对话的连续性、积累长期的知识,始终困扰着研究者和工程师。OpenClaw没有试图在算法层面解决这个难题,而是采用了一种工程化的"曲线救国"策略——既然模型本身有记忆限制,那就在模型之外构建一个外部记忆系统。这个系统的巧妙之处不在于技术的前沿性,而在于设计的人性化和实用性。
三重创新:从黑盒到白盒的范式转变
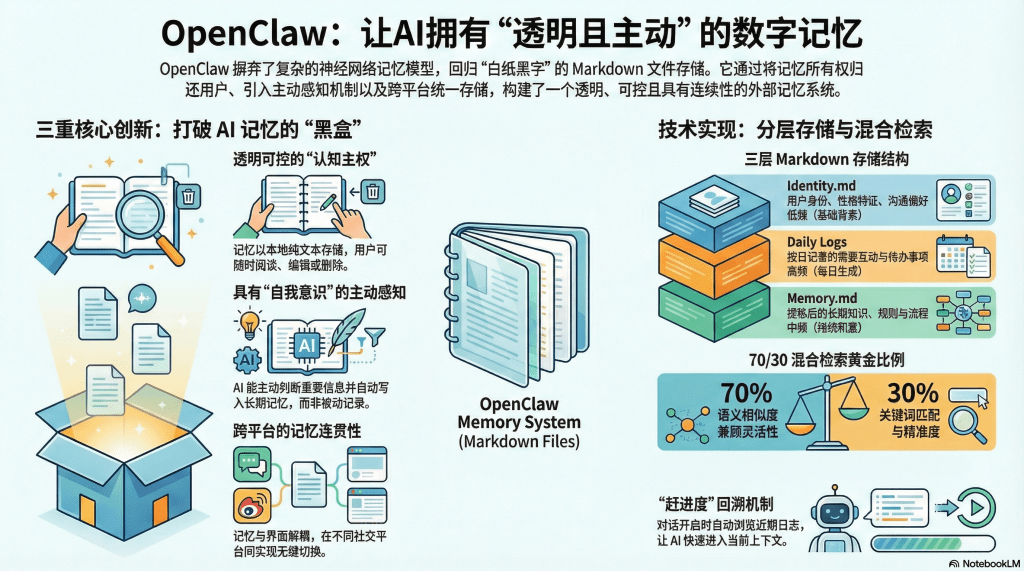
OpenClaw的记忆系统之所以引发广泛关注,是因为它在三个维度上进行了创新,每一个创新都击中了传统AI记忆系统的痛点。
透明可控:用户掌握的"认知主权"
传统AI助手(如ChatGPT、Claude、Gemini)的记忆机制对用户来说是一个黑盒。虽然这些产品都宣称具备"上下文理解"或"记忆功能",但用户无法直接查看AI到底记住了什么、如何存储这些信息、会在什么时候遗忘。这种不透明性带来了两个问题:
信任问题:用户不知道自己的哪些隐私信息被AI记录了,也不知道这些信息是否会被用于其他目的(如模型训练、广告推荐)。这种不确定性在隐私敏感的场景(如医疗咨询、法律咨询)中尤为严重。
可控问题:如果AI记错了某个重要信息(比如将你的工作单位记成了竞争对手),用户无法直接修正,只能通过反复对话"提醒"AI,但效果往往不理想。
OpenClaw的解决方案极其直接:将所有记忆以Markdown文本文件的形式存储在用户本地硬盘上。这些文件不是加密的二进制数据,而是用户可以直接打开、阅读、编辑的纯文本。就像翻开一个笔记本,你能清楚地看到每一页记录了什么。
这种设计的哲学意义深远。它将"记忆的所有权"从AI厂商转移回用户手中。用户不再是被动的信息提供者,而是主动的记忆管理者。如果发现AI对某个概念的理解有偏差,用户可以直接编辑Memory.md文件进行纠正;如果某段对话涉及敏感内容,用户可以手动删除对应的日志文件;如果想备份自己的"数字记忆",直接复制这些Markdown文件即可。
一位图书馆学教授在使用OpenClaw后感慨:"这是我第一次真正感受到'我的数据属于我自己'。我能看到AI对我的每一个判断,能修正它对我研究领域的误解,甚至能导出这些记忆用于其他工具。这种掌控感是任何商业AI都给不了的。"
主动感知:"我要把这个记下来"的自我意识
第二个创新是记忆的主动性。传统AI的记忆是被动的——它记录所有对话内容(受限于上下文窗口),但不会主动判断哪些信息值得长期保留。OpenClaw则表现出一种"自我意识"般的主动性。
在对话过程中,它会根据内容的重要性,主动判断是否需要写入长期记忆。例如:
- 用户随口提到"我在研究气候变化的社会影响",OpenClaw会判断这是一个重要的背景信息,自动写入常识库(Memory.md)。
- 用户说"这个Bug的解决方案是修改配置文件的第42行",OpenClaw会将这条技术细节记录到Daily Log中,方便未来查阅。
- 用户提供了一个复杂的工作流程(如"每周五下午生成周报并发送给团队"),OpenClaw会在心跳机制(Heartbeat.md)中设置定期任务。
更有趣的是,OpenClaw有时会明确告知用户它正在记录:"这个信息非常有用,我已经记在笔记里了。"这种"元认知"的表达,极大地增强了拟人化体验。用户感觉不是在使用一个工具,而是在与一个认真做笔记的助手合作。
这种主动记忆机制借鉴了人类认知心理学的"工作记忆"与"长期记忆"分离的模型。短期对话内容存储在模型的上下文窗口中(相当于工作记忆),而重要的、需要长期保留的信息则被提炼后写入文件(相当于长期记忆)。这种分层策略既保证了效率,又避免了信息过载。
跨平台连贯:消失的应用边界
第三个创新是记忆的统一性。传统AI助手的记忆通常绑定在特定平台上——你在ChatGPT网页版的对话记录,无法同步到手机App;你在Slack中与AI的交流,与在Discord中的对话完全隔离。这种碎片化严重损害了用户体验。
OpenClaw的记忆系统是平台无关的。无论你通过WhatsApp、Telegram、微信还是Discord与它交互,所有记忆都存储在同一套Markdown文件中。这意味着:
- 你可以在手机上通过WhatsApp询问"我昨天在电脑上讨论的那个项目进展如何",OpenClaw能准确回答,因为它调用的是同一个记忆库。
- 你可以在Telegram上开始一个任务,在Discord上继续,在微信上完成,整个过程AI都能保持上下文连贯。
- 即使切换到一个全新的平台(比如刚刚支持的Signal),历史记忆也能无缝迁移。
这种统一性对于工作和生活场景交织的现代人来说尤为重要。研究者可能在办公室用Slack与OpenClaw讨论学术问题,回家后用WhatsApp询问生活琐事,周末用Discord探讨兴趣爱好——但OpenClaw始终"知道"你是谁、你关心什么、你的工作进展到哪一步。它不会因为换了沟通工具就"失忆",这种连续性是传统多平台应用难以实现的。
从技术角度看,这种统一性得益于记忆与界面的解耦。记忆存储在本地文件系统中,各个IM平台只是与后端网关通信的"视图"。无论视图如何变化,底层的记忆数据始终保持一致。这与"Model-View-Controller"(MVC)架构的设计思想如出一辙——分离数据、逻辑和展示,实现高度的灵活性。
技术实现:大力出奇迹的工程智慧
OpenClaw的记忆系统在技术上并不复杂,甚至可以说是"笨拙"的——它没有使用最前沿的神经网络记忆模型,没有引入复杂的知识图谱,而是采用了最传统的文件系统和数据库技术。但正是这种"笨拙",成就了它的实用性和可靠性。
分层的文件存储结构
OpenClaw将记忆分为三个层次,每个层次对应不同的时间尺度和重要性级别:
Identity.md(身份记忆):这是关于"你是谁"的核心定义。它记录了用户的基本信息、性格特征、沟通偏好等相对稳定的内容。例如:
# 用户身份
- 姓名:张教授
- 职业:图书馆学教授,专注于数字人文研究
- 沟通风格:喜欢简洁直接的回答,不需要过多的客套
- 专业领域:信息检索、知识组织、AI在图书馆的应用
# Bot人设
- 角色:研究助理
- 语气:专业但友好,避免使用过于口语化的表达
- 特长:文献检索、数据分析、学术写作支持
这个文件通常手动创建或在初次对话时由AI生成,之后很少修改。它相当于AI对用户的"第一印象",为所有后续交互提供基础背景。
Daily Logs(工作日记):这是按时间组织的短期记忆。每天生成一个文件,如2026-02-06.md,记录当天的所有重要互动。例如:
# 2026年2月6日
## 上午
- 讨论了图书馆AI服务的架构设计
- 用户提到需要调研OpenClaw的技术细节
- 帮助整理了三篇相关技术博客的大纲
## 下午
- 完成了第一篇博客的初稿
- 用户对文风很满意,要求继续后续篇章
## 待办事项
- 完成剩余6篇博客(预计需要3-4天)
- 查找OpenClaw在学术界的相关讨论
这种日记式记录有两个好处:一是便于追溯("我们上周三讨论的那个问题是什么来着?"),二是便于AI自我复盘("今天遇到了什么问题?下次该如何改进?")。
Memory.md(常识库):这是长期有效的知识和规则的集合。它不按时间组织,而是按主题分类。例如:
# 工作流程
## 博客写作
- 用户偏好2000-3000字的深度文章
- 需要引用经典文献,但避免过于常见的诗词
- 强调逻辑性和可读性的平衡
## 技术偏好
- 使用Markdown格式
- 代码示例需要清晰注释
- 避免过多的行业黑话
# 研究项目
## 当前项目:图书馆AI驱动服务
- 预算有限,倾向于开源方案
- 关注隐私和数据主权问题
- 目标读者:图书馆员、社科研究者
常识库的内容会随着使用逐渐积累和完善。AI会定期审查日志,将反复出现的模式提炼为"常识"写入这个文件。这个过程类似于人类将短期记忆转化为长期记忆的"巩固"(Consolidation)过程。
混合检索策略:精准与灵活的平衡
拥有记忆只是第一步,如何高效地检索和使用这些记忆才是关键。OpenClaw采用了一套精巧的"混合检索"策略,结合了语义理解和关键词匹配的优势。
文本切片与向量化
首先,系统将三类Markdown文件切分成小块(Block),每块约400个Token(大约相当于一段中等长度的段落)。为了避免信息在切分边界处断裂,相邻块之间保留80个Token的重叠。
然后,对每个块进行两种处理:
- 语义向量化:使用Embedding模型(如OpenAI的text-embedding-3或开源的Sentence-BERT)将文本转换为高维向量。这个向量捕捉了文本的深层语义,即使用词不同但意思相近的内容,其向量也会很接近。
- 关键词提取:使用TF-IDF或BM25算法提取每个块中的关键词,并建立倒排索引。这使得精确的字符串匹配查询能够快速执行。
这些数据存储在本地的SQLite数据库中——一个轻量级但功能完备的关系型数据库,无需独立服务器,直接以文件形式嵌入应用。
70-30黄金比例
当用户提出问题时,系统会同时执行两种检索:
语义检索(70%权重):将问题也转换为向量,然后计算它与记忆库中所有块的余弦相似度,找出最相关的Top K个结果。这种方法的优势是"懂你的意思"——即使你换了一种说法,只要语义相近就能找到。
例如,用户问"上次那个关于日本料理的讨论",即使原始记录中没有"日本料理"这个词,而是写的"寿喜烧""和食",语义检索也能关联起来。
关键词检索(30%权重):使用传统的全文检索技术,查找包含特定词汇的块。这种方法的优势是"精准定位"——当你需要找一个具体的名词、数字或代码片段时,关键词匹配不会出错。
例如,用户问"那个SSH密钥的路径是什么",系统会直接找到包含"SSH""密钥""路径"这些词的记忆片段,而不会被语义相似但实际无关的内容干扰。
融合与排序
最后,系统将两种检索的结果按权重融合:语义结果占70%,关键词结果占30%。这个比例是经过实践检验的"黄金比例"——既保证了对自然语言问题的灵活理解,又避免了过度模糊导致的不准确。
融合后的结果按相关性排序,选出Top 3-5个最相关的记忆块,作为"上下文"注入到大模型的提示词中。这样,AI在回答问题时就能参考这些历史信息,表现出连续记忆的能力。
这个机制的巧妙之处在于,它是在模型之外实现的。无论使用的是Claude、GPT还是其他模型,只要能接受长提示词输入,就能享受到记忆系统的增强。这种架构的解耦性,正是工程设计的智慧所在。
"赶进度"的回溯机制
还有一个重要的技术细节是"Catch-up"(赶进度)机制。每当用户开启一个新的对话会话(Session),系统不会让AI从零开始,而是会:
- 读取最近三天的Daily Log,快速浏览发生了什么
- 提取当前未完成的任务列表
- 检查是否有需要提醒用户的事项
然后生成一个简短的"回顾"提示词,让AI在第一轮对话时就"进入状态"。这就像人类在会议开始前翻阅上次会议纪要,快速回忆上下文。
这个机制虽然简单,但效果显著。用户会发现,即使隔了几天没有使用OpenClaw,重新对话时AI也能立刻"接上话茬",仿佛从未离开过。这种无缝衔接的体验,是很多商业AI产品都难以提供的。
借鉴的技术谱系:站在巨人的肩膀上
OpenClaw的记忆系统并非横空出世,而是集成了多个领域的成熟技术。理解这些技术的来源,有助于我们评估其可靠性和未来演化方向。
RAG技术的工程实践
检索增强生成(Retrieval-Augmented Generation,RAG)是近年来NLP领域的热门技术。它的核心思想是:与其让模型记住所有知识(这会导致参数量爆炸和幻觉问题),不如在外部维护一个知识库,需要时检索相关内容再交给模型处理。
OpenClaw的记忆系统正是RAG的典型应用。它的创新不在于发明了RAG,而在于将这个学术概念工程化、产品化——用Markdown文件作为知识载体(而非传统的结构化数据库),用SQLite作为索引(而非专业的向量数据库如Pinecone),用混合检索平衡准确性和灵活性(而非单纯的向量检索)。
这些选择虽然"不够前沿",但极大地降低了系统的复杂度和成本。用户不需要部署额外的数据库服务器,不需要学习复杂的查询语言,甚至可以直接用文本编辑器修改知识库——这种"低技术门槛"正是OpenClaw能够快速普及的关键。
Claude Code的架构借鉴
Anthropic在2025年推出的Claude Code是OpenClaw的重要灵感来源。Claude Code演示了如何让AI控制计算机(读屏幕、操作鼠标、执行命令),这为OpenClaw的"主动性"提供了技术基础。
更重要的是,Claude Code处理上下文压缩和长期记忆的一些技巧被OpenClaw直接借鉴。例如,如何将长对话总结为简洁的要点、如何在有限的上下文窗口中塞入最相关的信息、如何避免重复发送相同内容导致Token浪费——这些"黑科技"很多都源自Claude Code的实践经验。
斯坦伯格在多次访谈中承认,OpenClaw在很大程度上是Claude Code的"开源精神继承者"。如果说Claude Code是一辆豪华轿车(功能强大但昂贵),那OpenClaw就是一辆改装的越野车(粗糙但实用,任何人都能上手改造)。
角色扮演Bot的人设技术
在二次元和虚拟偶像领域,开发者早就摸索出了一套"人设管理"的技术。如何让一个AI角色始终保持特定的性格、说话风格、行为模式?答案是维护一个详细的"设定文档",每次对话时都将这个设定作为系统提示词的一部分。
OpenClaw的Identity.md文件正是借鉴了这个思路。通过明确定义"用户是谁""Bot扮演什么角色",可以让AI的回复保持一致性,避免人格分裂。这对于长期使用的助手来说至关重要——如果AI今天说话像学者,明天像销售,后天像客服,用户会感到困惑和不适。
有趣的是,一些用户开始创造性地利用这个特性,为不同的工作场景配置不同的"人设"。比如,工作时使用严谨的"专业助理"人设,下班后切换到轻松的"生活伙伴"人设。虽然底层是同一个模型,但通过切换Identity文件,可以获得截然不同的交互体验。
本地优先的软件运动
OpenClaw的Markdown记忆系统还受到了"Local-First Software"运动的影响。这个运动由软件工程师Martin Kleppmann等人发起,主张软件应该将数据存储在用户本地,而非云端,以保障隐私、提高性能、确保离线可用。
Markdown作为一种纯文本格式,完美契合这个理念——它不依赖任何专有软件,可以用最简单的文本编辑器打开,可以轻松备份和迁移,可以纳入版本控制系统(如Git)进行变更追踪。即使OpenClaw项目停止维护,用户的记忆数据也不会丢失或变得无法访问。
这种对数据主权的尊重,在大数据和云计算主导的今天显得尤为珍贵。它提醒我们,技术进步不应以牺牲用户自主权为代价。
从工程到哲学:记忆主权的深层意义
OpenClaw的记忆系统虽然在技术上相对简单,但它提出了一些深刻的哲学问题,这些问题在AI时代变得越来越重要。
数据所有权的重新定义
在传统互联网服务中,用户数据的所有权是模糊的。虽然法律上可能规定"用户拥有其数据",但实际上,这些数据存储在公司服务器上,用户无法直接访问或控制。公司可以决定何时删除数据、如何使用数据、是否将数据用于训练模型。
OpenClaw的Markdown记忆文件彻底改变了这个权力关系。数据物理上存储在用户的硬盘上,用户拥有完全的读写权限,可以随时查看、备份、删除、甚至将其用于其他应用。这种"真正的所有权",比任何服务条款中的承诺都更有保障。
对于图书馆和学术机构来说,这个特性尤为重要。机构可以确保研究数据不会泄露给商业公司,可以建立自己的数据治理规范,可以在不违反隐私法规的前提下利用AI技术。这种数据主权的掌控,是采用云端SaaS服务无法实现的。
AI"人格"的可塑性与稳定性
人类的人格是在漫长的生活经历中逐渐形成的,具有相对的稳定性。但AI的"人格"(如果可以这么称呼的话)是完全可塑的——只要修改系统提示词,就能让它从严肃变得幽默,从保守变得激进。
OpenClaw的Identity.md文件将这种可塑性交给了用户。用户可以根据需要"塑造"AI的性格,甚至可以为不同场景创建不同的"人格配置文件"。这就像演员在不同角色间切换,但选择权在导演(用户)手中。
这种设计引发了一个有趣的问题:我们希望AI拥有一个固定的人格,还是可变的人格?固定人格带来一致性和信任感,但可能无法适应所有场景;可变人格提供了灵活性,但可能导致认同感的缺失。OpenClaw选择了后者,将选择权留给用户。这是一种民主化的设计理念——不预设答案,而是提供工具,让用户自己决定。
隐私保护与功能强大的张力
OpenClaw的记忆系统面临一个经典的两难:要让AI足够"聪明",就需要记录足够多的信息;但记录越多,隐私风险就越大。这个问题没有完美的解决方案,只能在两者之间寻求平衡。
OpenClaw的策略是赋予用户完全的控制权。用户可以:
- 查看并删除任何记忆片段
- 设置哪些信息不应被记录(如密码、敏感个人信息)
- 定期清理过时或不再需要的记忆
- 将记忆文件加密存储,只有在使用时才解密
这种"透明+控制"的组合,虽然不能完全消除隐私风险,但至少让风险变得可见、可管理。相比之下,商业AI的黑盒记忆让用户处于被动地位——你不知道它记住了什么,也无法确保它会遗忘。
对图书馆用户画像系统的启示
图书馆长期以来都在尝试构建"用户画像"系统,以便提供个性化服务。但这些系统往往面临两个挑战:一是数据孤岛(借阅记录、检索历史、咨询记录分散在不同系统),二是隐私顾虑(用户担心被过度追踪)。
OpenClaw的记忆系统提供了一个新思路:让用户掌握自己的画像。图书馆可以为每位用户提供一个"学术记忆库",记录他们的研究兴趣、阅读历史、学术网络等。关键是,这个记忆库的内容是透明的、可编辑的,用户可以决定哪些信息分享给图书馆的AI服务,哪些保留为私密。
这种"用户中心"的设计,既能实现个性化服务,又能尊重隐私权,可能是未来学术AI工具的标准模式。
结语:记忆的质地决定AI的温度
OpenClaw的记忆系统之所以成功,不是因为它使用了最先进的技术,而是因为它认真思考了"记忆"的本质——记忆不仅是数据的存储,更是关系的延续、信任的基础、自我的一部分。
通过将记忆做成白纸黑字的文件、通过赋予用户编辑和删除的权利、通过让AI主动判断什么值得记忆,OpenClaw创造了一种全新的人机关系——不是主人与奴仆,不是顾客与服务员,而更像是合作伙伴,共同维护着一个透明、可信的知识库。
对于考虑部署AI服务的图书馆和研究机构来说,OpenClaw的记忆设计提供了宝贵的借鉴:技术的先进性不如设计的人性化,功能的强大不如信任的建立。与其追求黑盒化的复杂算法,不如用简单、透明、可控的方式赢得用户的信赖。毕竟,在人与AI的长期共存中,信任才是最稀缺的资源。
在下一篇文章中,我们将聚焦OpenClaw最令人惊叹的特性——它的"活人感"。心跳机制如何让AI拥有主动性?这种设计能否成为未来的行业标准?AI大厂会如何回应这种创新?让我们一探究竟。
【下期预告】活人感的诞生——主动性、心跳机制与未来标准。我们将深入剖析OpenClaw如何通过技术手段实现"像人一样"的主动关怀,探讨这种创新在未来AI产品中的可能性与局限性,以及大厂的态度与市场格局的演变。

留下评论