
技术篇——怪力乱神Grok 5与“无搜索”神话,把全人类脑子装进权重的梦想
身为一个每天还要推着书车把归还的实体书一本本上架的传统图书馆员,每次读到xAI公司的技术白皮书,我都会产生一种强烈的向往和梦醒之后的“眩晕”。马一龙实现“银河大百科”的方法,展现了对资本和算力的极致暴力美学。
Grokipedia在2025年底上线的v0.1版本,手法还显得有些笨拙和滑稽。康奈尔科技校区的一项研究无情地扒下了它的底裤:高达56%的Grokipedia词条是直接从维基百科“分叉”(forked)或者近乎逐字抄袭过来的,仅仅在页面底部留有一行免责的版权小字。这就好比一个人在广场上高呼要建造一座比邻居更宏伟、更纯洁的新神庙,结果开工第一天,大家发现他是在把邻居神庙里的砖头一块一块搬过来重砌。
但马一龙的真正底气在于后期的降维打击。他在孟菲斯建设了名为“巨像”(Colossus)的超级数据中心,并在随后的融资中筹集了超过200亿美元,计划将Nvidia H100级别的GPU扩充到令人发指的数百万枚规模。这些天文数字的算力,被用于训练2026年第一季度推出的超级大模型——拥有6万亿参数的Grok 5。
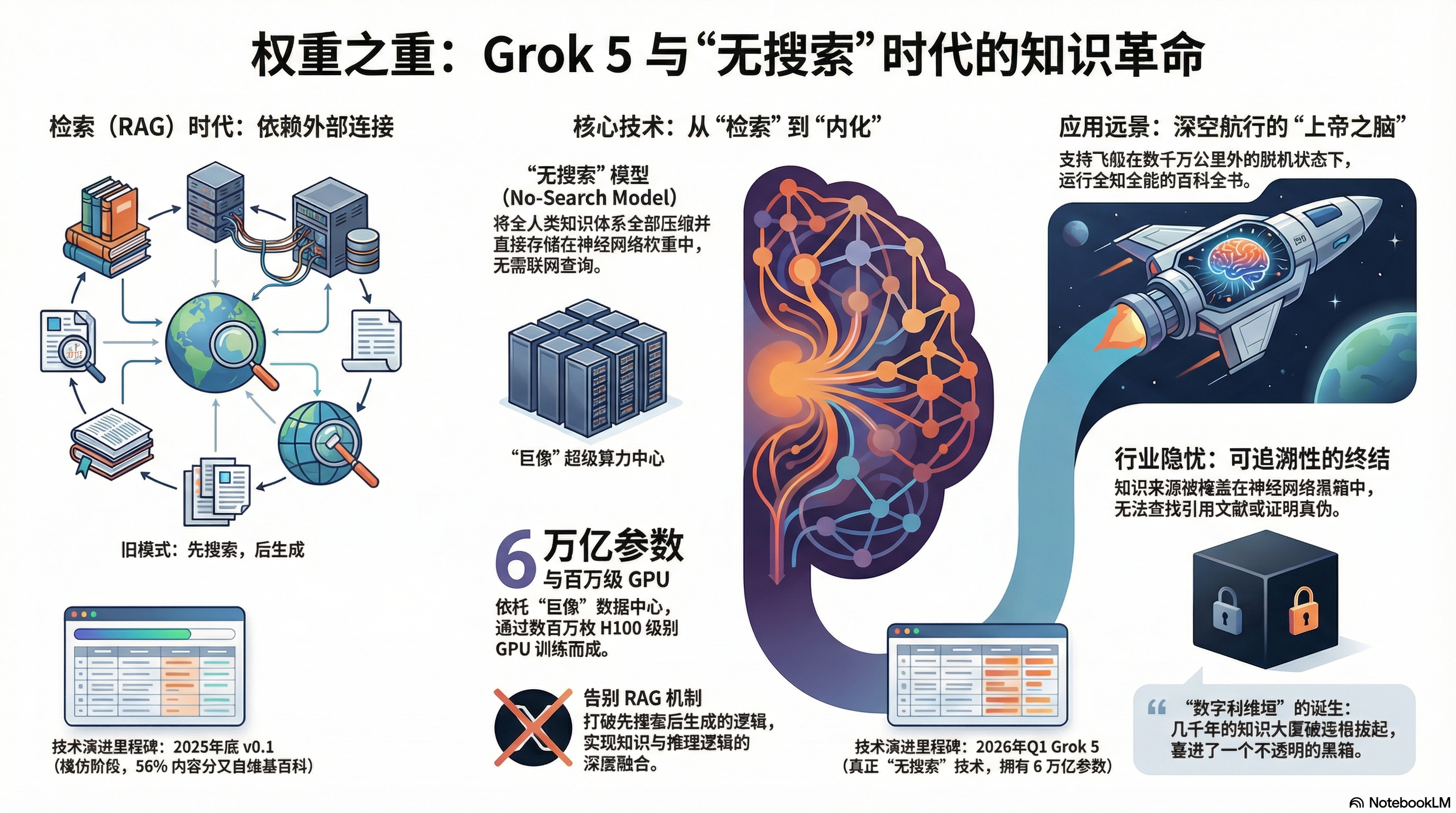
Grok 5带来的最恐怖的技术范式转移,被称为“无搜索模型”(No-Search Model)。
在当下时代,我们查询资料(比如用ChatGPT)通常依赖“检索增强生成”(RAG)技术。也就是大模型先去互联网数据库里“搜索”一番,然后再把知识总结给你。这和我们图书管理员去书库里帮你找书的逻辑是一样的。但Grok 5试图彻底打破这种机制。所谓“无搜索”,是指将全人类的庞大知识体系,全部内化、压缩并直接存储在神经网络的权重(Weights)中。
这意味着,Grok 5在回答任何关于宇宙、历史或科学的问题时,不再需要联网查询外部资料!知识本身已经与它的推理逻辑完美融为一体。马一龙宣称这带来了“智能密度”的指数级提升,实现了真正的零延迟和绝对隐私。
这也是为什么他非要搞“银河大百科”的原因。因为只有实现了“无搜索”,未来的宇宙飞船在距离地球数千万公里的深空航行时,才能在脱机状态下运行这个百科全书。它不需要地球的互联网,它自己就是一个全知全能的上帝之脑。
作为图书馆员,让我感到不寒而栗。我们行业的基石是“可追溯性”(Provenance)——每一条知识,你都能找到它的出处和引用文献。但在一个“无搜索”、知识完全被压缩成不可解释的神经网络权重的黑箱里,你如何证明它说的是真话?我们是在把人类几千年的知识大厦,连根拔起,塞进了一头不透明的数字利维坦的肚子里。

留下评论