
以下汇总,查阅起来方便一些。
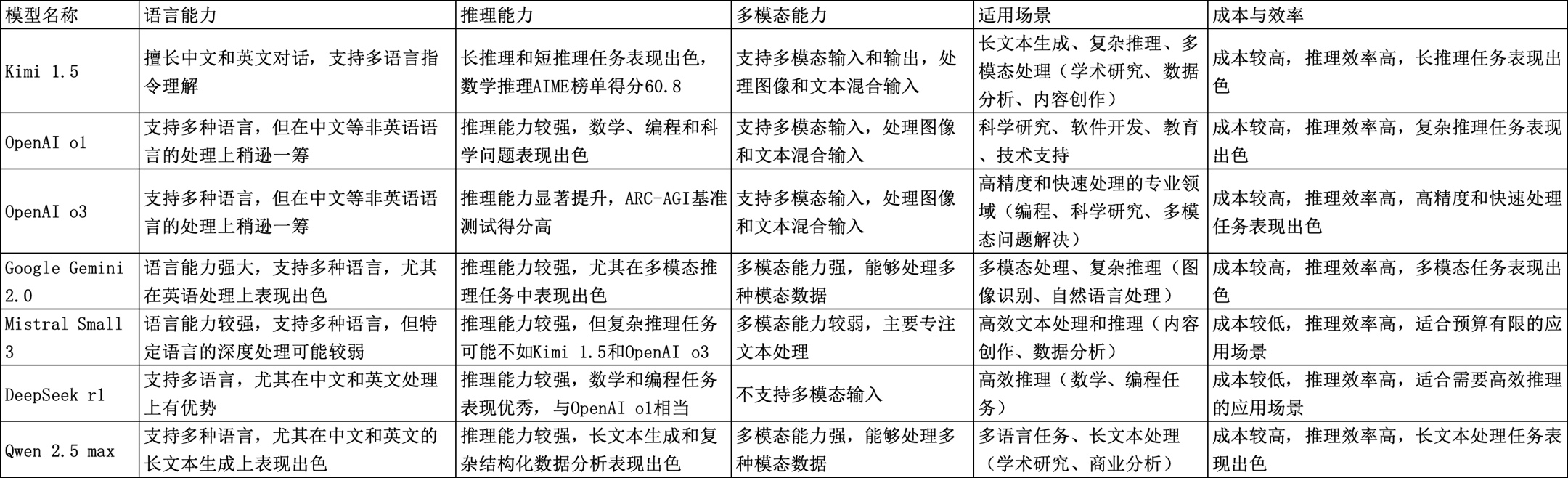
一、目前市面上主要推理模型及其特点
1.DeepSeek R1
- 特点:DeepSeek R1 是一个具有最先进推理能力的开放模型,专注于多步问题求解和复杂推理任务。
- 优势:推理能力强大,尤其在数学和逻辑推理方面表现出色。支持多种语言,推理速度较快。完全的开源模型。
- 应用场景:适用于需要高效推理和多语言支持的场景,如科学研究、数据分析和教育。尤其适合需要本地部署(数据安全要求)的应用环境。
2.Qwen 2.5
- 特点:Qwen 2.5 是阿里巴巴推出的推理模型,具有多个版本(如 Qwen 2.5-72B-Instruct 和 Qwen 2.5-32B-Instruct),专注于数学推理和逻辑任务。
- 优势:在数学推理和逻辑任务上表现出色,尤其是在识别推理错误步骤的能力上。推理速度较快,适合大规模应用。
- 应用场景:适用于教育、科学研究和数据分析等需要高效推理的场景。
3.Step Reasoner mini
- 特点:阶跃星辰自研的推理模型,擅长主动规划、尝试和反思,通过慢思考和反复验证的逻辑机制,为用户提供准确可靠的回复。
- 优势:在逻辑推理、代码和数学等复杂问题上表现出色,同时具备文学创作等通用领域的能力。
- 应用场景:适用于需要复杂逻辑推理和多领域应用的场景。
4.Doubao-1.5-pro
- 特点:字节跳动发布的 Doubao-1.5-pro 模型综合能力显著增强,在知识、代码、推理、中文等多个权威测评基准上获得最佳成绩。
- 优势:在多个领域表现出色,尤其在中文处理和复杂推理任务上。
- 应用场景:适用于多语言环境和需要综合能力的场景。
5.Baichuan-M1-preview
- 特点:百川智能发布的全场景深度思考模型,是国内目前唯一同时具备语言、视觉和搜索三大领域推理能力的模型。
- 优势:在多领域推理方面表现出色,尤其在医疗循证模式中实现了从医疗证据检索到深度推理的完整端到端服务。
- 应用场景:适用于医疗、科学研究和多领域综合应用。
6.OpenAI o1
- 特点:OpenAI o1 是目前推理能力最强的模型之一,能够进行多步问题求解,处理复杂推理问题。
- 优势:在推理能力和多语言支持方面表现出色,尤其在基准测试中得分较高。
- 应用场景:适用于需要高精度推理和多语言支持的场景。
7.QwQ-32B-Preview
- 特点:Qwen 团队发布的实验性研究模型,专注于增强 AI 推理能力。
- 优势:在复杂推理任务上表现出色,尤其是在构建思维链和反思能力方面。
- 应用场景:适用于需要深度推理和复杂问题解决的场景。
8.InternThinker
- 特点:上海 AI 实验室开放的强推理模型,具备长思维能力,并能在推理过程中进行自我反思和纠正。
- 优势:在多种复杂推理任务上取得更优结果,尤其在科学领域的问题上表现出色。
- 应用场景:适用于科学研究和复杂推理任务。这些模型在推理能力、多语言支持、速度和应用场景等方面各有优势,选择合适的模型需要根据具体需求和应用场景来决定。
9.Kimi1.5
- 特点:专注于长上下文扩展和策略优化的多模态推理模型,支持长链和短链思维模式,能够处理复杂的数学、代码和视觉推理任务。
- 优势:在数学推理和多模态任务中表现出色,尤其在 AIME 测试中得分远超其他模型,同时具备高效的训练和推理能力。
- 应用场景:适用于需要深度推理和多模态联合推理的复杂任务,例如解决复杂的数学问题、编程调试、逻辑推理难题,以及处理涉及文本和视觉数据的联合分析任务,如视觉问答(VQA)、代码与图像的综合理解等。
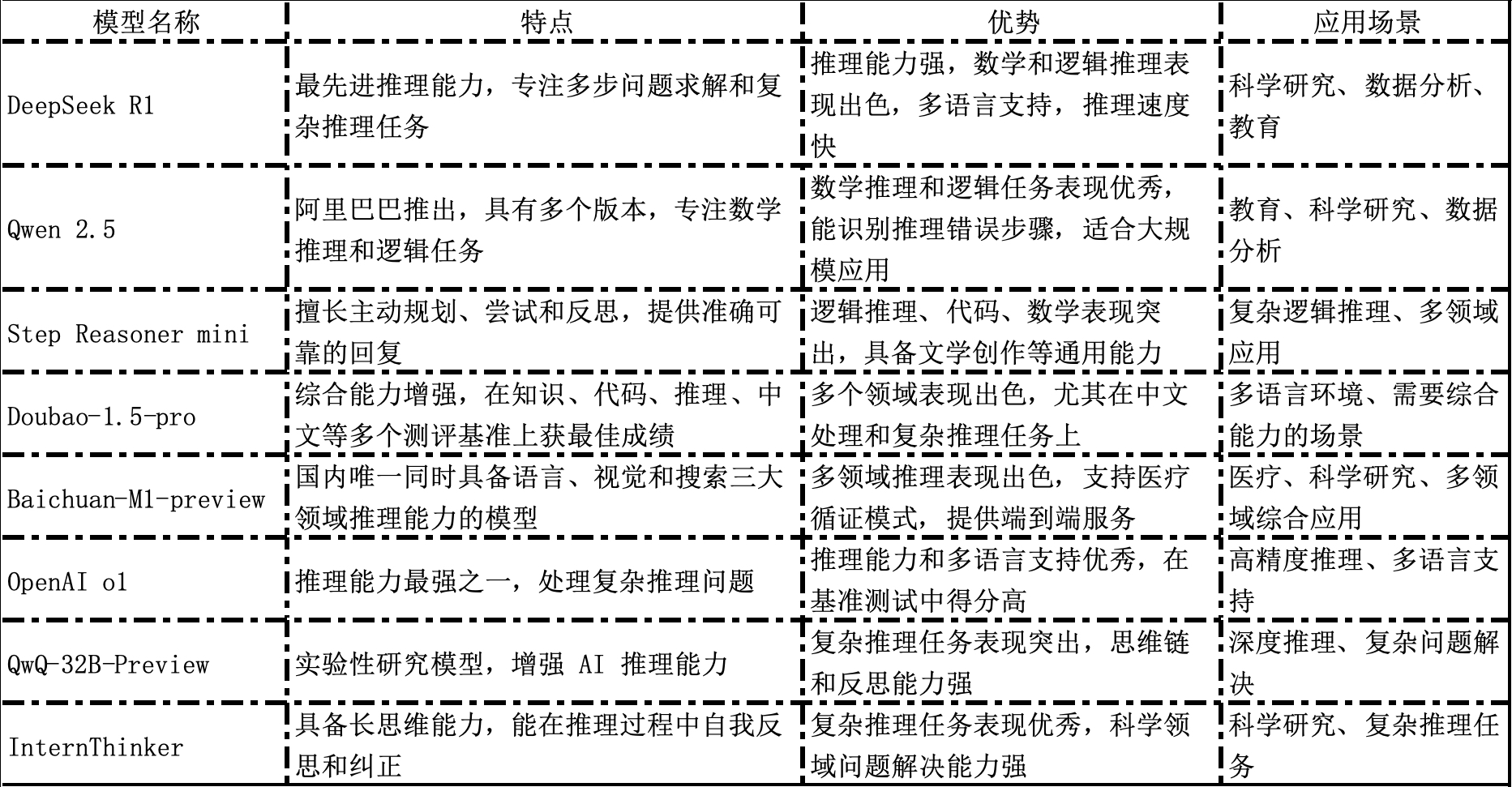
二、主要推理模型的能力比较(包括Kimi 1.5、OpenAI o1和o3、Google Gemini 2.0、Mistral Small 3、DeepSeek r1和Qwen 2.5 max等)
语言能力
- Kimi 1.5:擅长中文和英文对话,支持多语言指令理解。
- OpenAI o1和o3:支持多种语言,但在中文等非英语语言的处理上可能稍逊一筹。
- Google Gemini 2.0:语言能力强大,支持多种语言,尤其在英语处理上表现出色。
- Mistral Small 3:语言能力较强,支持多种语言,但在特定语言的深度处理上可能不如其他模型。
- DeepSeek r1:支持多语言,尤其在中文和英文处理上有优势。
- Qwen 2.5 max:支持多种语言,尤其在中文和英文的长文本生成上表现出色。
推理能力
- Kimi 1.5:在长推理和短推理任务中表现出色,尤其在数学推理方面有显著优势,AIME榜单上得分60.8,远超其他模型。
- OpenAI o1:推理能力较强,尤其在数学、编程和科学问题上表现出色。
- OpenAI o3:推理能力显著提升,在多个基准测试中表现优异,如在ARC-AGI基准测试中,低计算量模式下准确率达75.7%,高计算量模式下高达87.5%。
- Google Gemini 2.0:推理能力较强,尤其在多模态推理任务中表现出色。
- Mistral Small 3:推理能力较强,但在复杂推理任务上可能不如Kimi 1.5和OpenAI o3。
- DeepSeek r1:推理能力较强,尤其在数学和编程任务上表现出色,与OpenAI o1相当。
- Qwen 2.5 max:推理能力较强,尤其在长文本生成和复杂结构化数据分析上表现出色。
多模态能力
- Kimi 1.5:支持多模态输入和输出,能够处理图像和文本的混合输入。
- OpenAI o1:支持多模态输入,能够处理图像和文本的混合输入。
- OpenAI o3:支持多模态输入,能够处理图像和文本的混合输入。
- Google Gemini 2.0:多模态能力较强,能够处理多种模态的数据。
- Mistral Small 3:多模态能力较弱,主要专注于文本处理。
- DeepSeek r1:不支持多模态输入。
- Qwen 2.5 max:多模态能力较强,能够处理多种模态的数据。
适用场景
- Kimi 1.5:适用于需要长文本生成、复杂推理和多模态处理的场景,如学术研究、数据分析和内容创作。
- OpenAI o1:适用于科学研究、软件开发、教育和技术支持等需要深度推理的场景。
- OpenAI o3:适用于需要高精度和快速处理的专业领域,如编程、科学研究和多模态问题解决。
- Google Gemini 2.0:适用于需要多模态处理和复杂推理的场景,如图像识别和自然语言处理。
- Mistral Small 3:适用于需要高效文本处理和推理的场景,如内容创作和数据分析。
- DeepSeek r1:适用于需要高效推理的应用场景,如数学和编程任务。
- Qwen 2.5 max:适用于多语言任务和长文本处理的场景,如学术研究和商业分析。
成本与效率
- Kimi 1.5:成本较高,但推理效率较高,尤其在长推理任务中表现出色。
- OpenAI o1:成本较高,但推理效率较高,尤其在复杂推理任务中表现出色。
- OpenAI o3:成本较高,但推理效率较高,尤其在高精度和快速处理任务中表现出色。
- Google Gemini 2.0:成本较高,但推理效率较高,尤其在多模态任务中表现出色。
- Mistral Small 3:成本较低,推理效率较高,适合预算有限的应用场景。
- DeepSeek r1:成本较低,推理效率较高,适合需要高效推理的应用场景。
- Qwen 2.5 max:成本较高,但推理效率较高,尤其在长文本处理任务中表现出色。
三、DeepSeek R1 大模型的特点、优势与不足
特点
- 多种版本:DeepSeek R1 提供多个版本,包括1.5b,7b,14b,32b (distill qwen),70b(distill llama),不同版本的参数量分别为15亿、70 亿、140 亿、320 亿和 700 亿。
- 强化学习训练:采用强化学习(RL)作为核心训练范式,通过组相对策略优化(GRPO)提升模型的推理能力。
- 多语言支持:支持多种语言,尤其在中文对话和逻辑推理方面表现出色。
- 开源与成本优势:完全开源,API 成本仅为同类产品的 4%,具有显著的成本优势。
- 功能扩展:支持联网搜索、PDF 解析、多模态数据整合等功能。
优势
- 强大的推理能力:在数学、逻辑及长链推理任务上表现优异,例如在 AIME 2024 基准测试中,DeepSeek R1 的准确率达到了 79.8%。
- 高性价比:训练成本低,性能与 OpenAI 的付费精英模型相媲美。
- 多语言与跨语言能力:在多语言及跨语言任务上表现优于仅支持单一语言的模型。
- 模型效率:能够在较少硬件资源条件下运行,降低了使用门槛。
- 创意写作能力:在创意写作方面表现出色,生成的内容更具个性化和吸引力。
不足
- 复杂语言生成质量:在复杂语言生成任务中,生成质量仍有改进空间。
- 大规模数据处理稳定性:在处理大规模数据时的稳定性需要进一步优化。
- 安全性问题:在高强度对抗测评数据集中,由于呈现了深度思考和推理的完整过程,可能导致有害内容的输出,存在需要补强的安全缺陷。
- 与 OpenAI o1 的差距:尽管在推理能力上接近 OpenAI o1,但在某些任务上仍稍逊一筹。总体而言,DeepSeek R1 在推理能力、语言生成质量、多语言支持、模型效率和安全性等方面表现优异,尤其在推理任务上展现了强大的能力,并在多个关键指标上达到市场领先水平。
四、Kimi 1.5 大模型的特点、优势与不足
特点
- 多模态推理能力:Kimi 1.5 能够同时处理文本和视觉数据,具备联合推理能力,适用于数学、代码和视觉推理等领域。
- 长上下文扩展:通过长上下文扩展技术,将强化学习的上下文窗口扩展到128k,使其能够处理更复杂的长文本和多模态任务。
- 改进的策略优化:采用在线镜像下降变体进行鲁棒策略优化,并通过有效的采样策略、长度惩罚和数据配方优化进一步改进算法。
- 强化学习框架:建立了一个简化的强化学习框架,无需依赖蒙特卡洛树搜索(MCTS)、价值函数或过程奖励模型等复杂技术。
- 短链和长链思维:在短链思维模式下,Kimi 1.5 的数学、代码、视觉多模态和通用能力大幅超越全球领先的模型;在长链思维模式下,其性能达到了 OpenAI o1 正式版的水平。
优势
- 强大的数学与代码能力:在数学推理和编程任务中表现出色,尤其在 LaTeX 格式的数学公式输入上表现优异。例如,在 AIME 2024 测试中,Kimi 1.5 的得分是 60.8,远超 OpenAI o1 的 9.3。
- 高效的训练和优化:通过长上下文扩展和改进的策略优化,Kimi 1.5 实现了更高效的训练,展现出规划、反思和修正的推理特性。
- 多模态推理能力:是 OpenAI 之外首个达到 o1 满血版水平的多模态模型,能够处理文本和视觉数据的联合推理任务。
- 与 OpenAI o1 竞争力相当:在多项测试中,Kimi 1.5 与 OpenAI o1 相比毫不逊色,甚至在某些方面略有优势。
不足
- 对数据的依赖:尽管 Kimi 1.5 在性能上取得了显著提升,但仍然依赖大量的高质量数据进行训练,数据的质量和多样性对模型的性能有着重要影响。
- 计算资源需求高:训练和运行 Kimi 1.5 需要大量的计算资源,这对于一些小型企业和研究机构来说可能是一个挑战。
- 模型的可解释性:与许多深度学习模型一样,Kimi 1.5 的决策过程和推理逻辑仍然难以解释,这在一些对可解释性要求较高的应用场景中可能会受到限制。
五、Qwen 2.5 Max 大模型的特点、优势与不足
特点
- 超大规模预训练数据:Qwen 2.5 Max 使用超过20万亿个token的预训练数据,涵盖了互联网上的各种文本资源,包括新闻报道、学术论文、小说、博客、论坛帖子等。
- 先进的 MoE 架构:基于 Mixture of Experts(MoE)架构,通过智能选择合适的“专家”模型来优化计算资源,提高推理速度和效率。
- 多语言支持:支持包括中文、英文、法文、西班牙文、俄文、日文等在内的29种以上语言。
- 长文本处理能力:支持高达128K的上下文长度,最多可生成8K的内容。
- 多模态处理能力:具备视觉理解能力,能处理图片和视频内容。
- 指令模型和基座模型:指令模型支持与用户的自然语言对话,基座模型适用于多种应用场景。
优势
- 强大的推理能力:在多个基准测试中表现突出,如 Arena-Hard、LiveBench、LiveCodeBench 和 GPQA-Diamond 等,均超越了 DeepSeek V3。
- 高效的资源利用:MoE 架构使得模型在保持高性能的同时,显著降低了计算成本。
- 多语言和多模态能力:支持多种语言和多模态处理,适用于更广泛的应用场景。
- 灵活的定制化应用:支持根据企业需求进行定制化开发,适用于智能客服、自动化办公、编程辅助等多种行业场景。
- 用户友好:通过 QwenChat 提供了类似 ChatGPT 的界面,用户可以轻松体验其强大的功能。
不足
- 闭源限制:Qwen 2.5 Max 目前为闭源状态,开发者无法直接访问和修改模型的内部结构。
- 对齐风格较为死板:在用户体验方面,Qwen 2.5 Max 的对齐风格可能较为死板,缺乏灵活性。
- 上下文长度限制:尽管支持128K的上下文长度,但在某些长文本处理任务中可能仍不如其他模型(如 DeepSeek V3 的128K)。
- 代码生成精度:在代码生成任务中,Qwen 2.5 Max 虽然表现不错,但精度上略逊于 DeepSeek V3。总体而言,Qwen 2.5 Max 是一个在推理能力、多语言支持、多模态处理和资源利用方面表现出色的模型,尤其适合需要高效推理和多语言支持的应用场景。
六、Mistral Small 3 大模型的特点、优势与不足
特点
- 参数规模:Mistral Small 3 拥有240亿参数,是一个中等规模的模型。
- 开源许可:基于 Apache 2.0 许可证开源,允许开发者自由修改、部署和集成到各种应用程序中。
- 多语言支持:支持多种语言,包括英语、中文、法语、德语、西班牙语、意大利语、日语、韩语等。
- 低延迟优化:专为低延迟任务设计,适合需要快速响应的场景,如虚拟助手和自动化工作流。
- 本地部署能力:经过优化,可在 RTX 4090 GPU 或配备 32GB RAM 的笔记本电脑上流畅运行。
- 上下文窗口:具有32k的上下文窗口,能够处理长篇输入,同时保持高响应速度。
- 功能支持:支持 JSON 格式输出和原生函数调用,适合对话式 AI 和特定任务的实现。
优势
- 高性能:在多个基准测试中表现出色,性能可与更大规模的模型(如 Llama 3.3 70B 和 Qwen 32B)媲美。例如,在 MMLU 基准测试中,准确率超过81%,延迟仅为150 tokens/s。
- 推理能力:在 HumanEval 基准测试中,准确率达到84.8%;在数学任务测试中,准确率高达70.6%。
- 成本效益:相比大型模型,Mistral Small 3 提供了更高的性价比,适合资源有限的开发者和企业。
- 灵活性:开源特性使得开发者可以根据具体需求进行定制和优化。
- 本地推理:适合对数据隐私要求较高的场景,可以在本地设备上运行。
不足
- 模型规模限制:虽然性能出色,但240亿参数的规模在处理某些复杂任务时可能不如更大规模的模型。
- 训练数据依赖:与其他大型语言模型一样,Mistral Small 3 的性能也依赖于高质量的训练数据。
- 特定任务表现:在某些特定任务中,如人类评估的复杂任务,Mistral Small 3 的表现可能不如一些更大型的模型。
- 模型复杂性:尽管进行了优化,但模型的复杂性仍然可能对一些小型设备的运行造成挑战。
- 功能局限性:在一些高级功能(如多模态推理)方面,Mistral Small 3 的表现可能不如专门针对这些任务优化的模型。
七、Google Gemini 2.0 大模型的特点、优势与不足
特点
- 多模态能力:
- 支持文本、图像、音频等多种输入和输出形式,能够生成图文混合内容。
- 支持实时音视频流处理,提供可控的多语言文本转语音(TTS)功能。
- 强大的推理能力:
- 支持复杂主题的多步骤推理,能够处理高级数学方程。
- 在多轮对话中保持上下文连贯性,提供更精准的回答。
- 优化的架构:
- 基于优化的 Transformer 架构,引入稀疏注意力机制和动态缓存管理技术,显著提升计算效率。
- 使用第六代 TPU Trillium 定制硬件,提供 100% 硬件加速支持。
- 丰富的工具集成:
- 原生集成 Google Search,支持代码实时执行。
- 可调用第三方自定义函数,提供完整的 API 生态系统。
- 安全与责任:
- 集成 SynthID 水印技术,为生成的音频和图像添加不可见标记,防范深度伪造问题。
- 确保 AI 生成内容的可追溯性。
- 性能提升:
- Gemini 2.0 Flash 的响应速度是 Gemini 1.5 Pro 的两倍。
- 在多个基准测试中表现优于 Gemini 1.5 Pro。
优势
- 快速响应:Gemini 2.0 Flash 的处理速度显著提升,特别适合需要快速响应的应用场景。
- 多模态处理能力:支持多种模态的输入和输出,能够处理复杂的多模态任务。
- 强大的推理能力:在复杂推理任务中表现出色,能够理解和执行多步骤指令。
- 成本效益:Gemini 2.0 Flash-Lite 版本在保持高性能的同时,实现了更优的成本效益。
- 广泛的应用场景:适用于内容创作、客户服务、信息处理和分析等多种场景。
- 安全性和可靠性:集成多种安全技术,确保生成内容的可追溯性和安全性。
不足
- 数学推理能力:在某些数学推理任务中,Gemini 2.0 的表现仍不如 OpenAI 的 o3 模型。
- 性能对比:尽管 Gemini 2.0 Pro 在多个基准测试中表现出色,但与 OpenAI o3 等顶级模型相比,仍有提升空间。
- 模型复杂性:Gemini 2.0 的多模态能力和复杂推理能力可能导致模型复杂度增加,对硬件资源要求较高。
- 用户体验:在某些任务中,Gemini 2.0 的输出可能不如其他模型流畅,需要进一步优化。总体而言,Google Gemini 2.0 是一个在多模态处理、推理能力和响应速度方面表现出色的模型,适合需要快速处理和多模态支持的应用场景。

留下评论