
两天之间
2026年4月23日,旧金山。
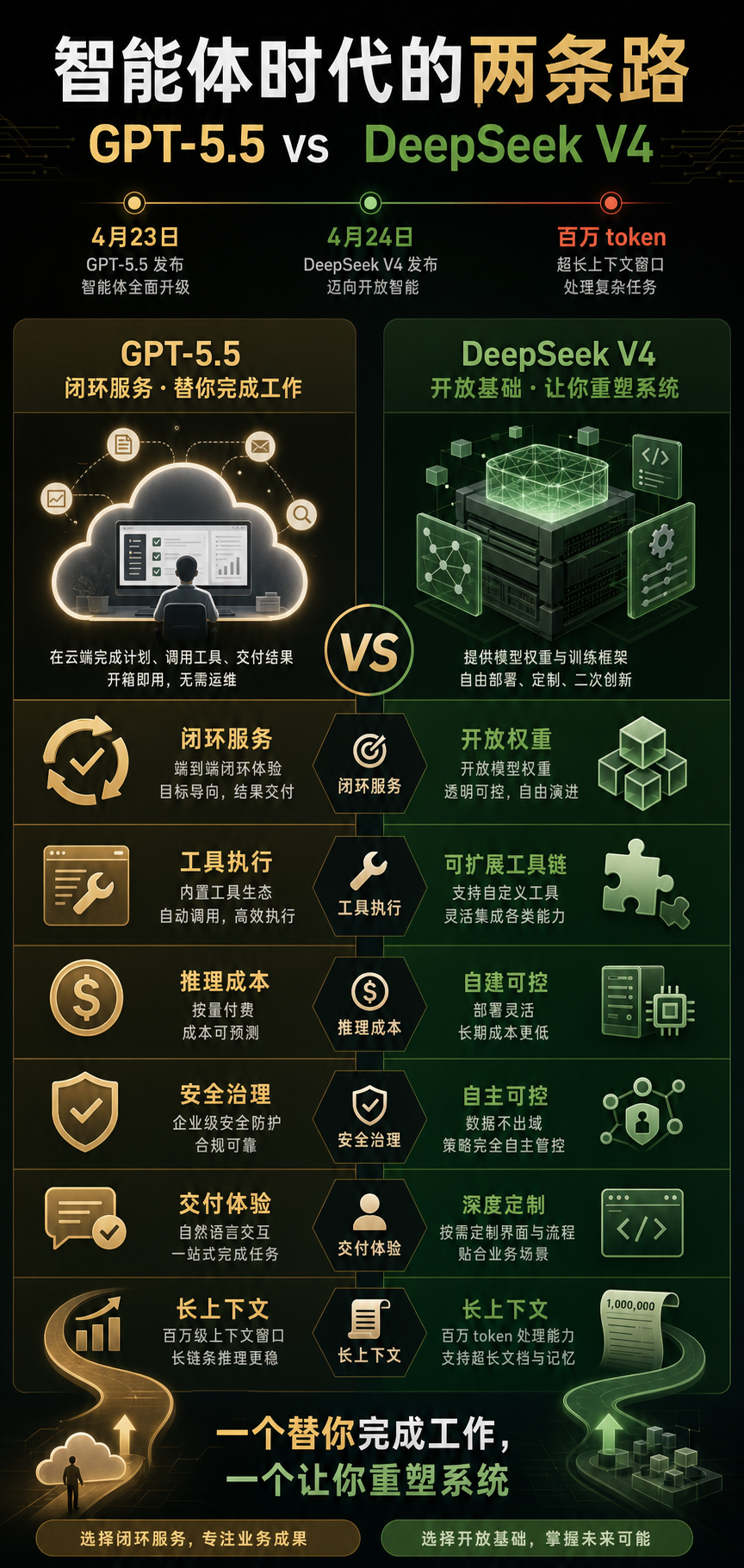
OpenAI 把一个新名字推到台前:GPT-5.5。官方标题很克制,叫“a new class of intelligence for real work”。但这句话真正的意思并不克制:OpenAI 不再只想发布一个更会聊天的模型,它想把 ChatGPT 和 Codex 变成一种新的工作操作系统。
二十四小时后,4月24日,杭州与全球开发者社区的时间线同时跳动。DeepSeek V4 Preview 出现在 Hugging Face、API 文档和媒体报道里。不是一个版本,而是两个:Pro 与 Flash。一个更重,一个更快。共同的招牌是一个惊人的数字:一百万 token 上下文。
这两天像一场精心剪辑过的电影。
第一幕,美国公司说:模型要学会自己做事。
第二幕,中国公司说:那就给它足够长的记忆,并把权重放出来。
表面看,这是 GPT-5.5 对 DeepSeek V4。更深一层看,这是两种 AI 工业路线的正面相遇:一个押注封闭式超级服务,一个押注开放式基础设施;一个强调“我能替你完成工作”,一个强调“你可以把我部署进你的世界”。
问题是,谁更接近下一代 AI 的入口?
OpenAI 的新按钮
GPT-5.5 最值得注意的地方,不是它在某个榜单上又赢了几分。
当然,榜单很漂亮。OpenAI 在官方发布中称,GPT-5.5 在 Terminal-Bench 2.0 达到 82.7%,高于 GPT-5.4 的 75.1%;在 BrowseComp 上 GPT-5.5 Pro 达到 90.1%;在 FrontierMath 更高难度层级上也有提升。对于普通读者,这些数字像机场屏幕上的航班编号,看得见,却很难记住。
真正值得记住的是另一个变化:GPT-5.5 被描述成一个能“计划、使用工具、检查工作、穿过模糊性并继续执行”的模型。
这不是聊天机器人的语言。
这是雇员的语言。
过去几年,大模型行业一直在追逐三个词:reasoning、coding、agent。推理让模型能想得更久,编程让模型能改造数字世界,智能体则让模型从“回答问题”走向“完成任务”。GPT-5.5 的发布,像是在这三个词之间画了一条线:如果一个模型能理解需求、写代码、查资料、操作软件、生成文档和表格,并且在失败后自我纠错,那么它就不再只是一个接口。
它变成了一个工作循环。
你给它一个目标,它自己拆解。你给它一堆混乱材料,它自己整理。你让它进入一个代码库,它不是只写一段漂亮函数,而是读上下文、跑测试、看报错、再修。
这正是 OpenAI 想要的叙事:AI 不是副驾驶,而是第一位真正能接管长流程工作的数字同事。
Codex 里的肌肉
GPT-5.5 的锋芒首先露在代码里。
OpenAI 说它是目前最强的 agentic coding model。这个表述很微妙。不是“最会写代码”,而是“最会以智能体方式写代码”。
差别在哪里?
一个会写代码的模型,像一位数学竞赛选手。你给题,它解题。
一个会做 agentic coding 的模型,像一个被扔进陌生仓库的工程师。它要先找灯,翻图纸,确认哪根管道漏水,再决定从哪里下扳手。
真实软件工程的困难,从来不只是“生成正确代码”。困难在于不知道问题在哪里,不知道测试为什么失败,不知道旧代码里哪一行是历史包袱,哪一行是业务契约。一个模型如果不能在文件、终端、测试、错误日志和需求之间来回移动,再高的单题能力也会被现实磨平。
所以 GPT-5.5 的重点不是它能写一个函数,而是它能在 Codex 中连续工作。OpenAI 还强调,它在完成相同 Codex 任务时使用更少 token,并且在真实服务中保持接近 GPT-5.4 的每 token 延迟。
这句话背后是一门不太性感、但极其昂贵的学问:推理效率。
模型越聪明,通常越慢、越贵、越难大规模服务。OpenAI 这次把 GPT-5.5 和 NVIDIA GB200、GB300 NVL72 系统放在同一个故事里讲,等于承认了一件事:前沿模型竞争已经不是“谁有一个更好的神经网络”这么简单。
它是模型、芯片、推理系统、产品入口和安全机制的联合作战。
OpenAI 的城墙不只在参数里,也在数据中心里。
DeepSeek 的长卷轴
如果说 GPT-5.5 像一个穿着公司工牌、接入所有办公软件的数字员工,那么 DeepSeek V4 更像一卷被摊开的超长地图。
DeepSeek V4 Preview 的两个核心版本很清楚:V4-Pro 与 V4-Flash。根据 Hugging Face 上 deepseek-ai 的模型卡,V4-Pro 是 1.6T 总参数、49B 激活参数的 MoE 模型;V4-Flash 是 284B 总参数、13B 激活参数。两者都支持一百万 token 上下文。
一百万 token 是什么概念?
它不是“能多读几页 PDF”。它更像把一本书、一组代码仓库、一整段工具调用历史、若干份会议纪要和长篇技术报告放进同一个房间,让模型不必每五分钟失忆一次。
但长上下文有一个残酷问题:记忆不是免费的。
当一个智能体不断调用工具、读取文件、追加日志时,它的上下文会像雪球一样滚大。每一次生成新 token,都要回看前面的海量内容。KV cache 像仓库租金,token 越多,租金越高。很多“长上下文模型”在宣传页上很好看,一到真实 agent 工作流里就变成昂贵的慢动作。
DeepSeek V4 的技术叙事正是冲着这个痛点去的。模型卡称,V4 使用混合注意力架构,把 Compressed Sparse Attention 与 Heavily Compressed Attention 结合起来;在一百万 token 场景下,V4-Pro 相比 DeepSeek-V3.2 只需要 27% 的单 token 推理 FLOPs 和 10% 的 KV cache,V4-Flash 进一步降到 10% FLOPs 与 7% KV cache。
如果这些数字在独立评测和生产部署中站得住,它的意义不只是“上下文变长了”。
它意味着开放模型终于开始认真处理智能体的基础设施账单。
一个要闭环,一个要铺路
GPT-5.5 与 DeepSeek V4 的差异,可以用一个简单比喻解释。
OpenAI 在建一辆自动驾驶卡车。方向盘、地图、引擎、保险、调度中心都由它来控制。你买的是运输能力,不必关心发动机怎么装。
DeepSeek 在卖一套可以拆开的动力总成。你可以把它装进自己的车、自己的工厂、自己的机器人,甚至改装成奇怪但有用的机器。代价是,你要懂维修,也要承担更多风险。
因此两者竞争的不是同一种用户。
GPT-5.5 先面向 ChatGPT Plus、Pro、Business、Enterprise 和 Codex 用户滚动开放,API 还需要等待安全和规模化部署安排。它的产品重心是“把复杂任务拿走”。企业喜欢这种东西,因为采购逻辑清楚:我付费,你交付能力,你负责安全、速度和稳定性。
DeepSeek V4 Preview 则更像给开发者和云厂商的一封信:权重在这里,模型在这里,长上下文在这里,Pro 和 Flash 两档在这里。你可以评测、微调、部署、适配硬件、封装成自己的智能体平台。
一个是服务逻辑。
一个是生态逻辑。
这也是为什么 DeepSeek V4 与华为 Ascend 的关系会引发关注。媒体报道称,V4 已适配华为芯片技术,华为也表示 Ascend 系统支持 DeepSeek V4 系列。这里必须谨慎:这并不等于每一次训练或部署都只发生在华为硬件上,DeepSeek 也没有完全公开训练硬件细节。但它释放的信号足够明确:中国 AI 公司正在试图把模型能力与本土计算栈绑定得更紧。
在芯片禁令和地缘竞争的背景下,这不只是技术新闻。
这是供应链新闻。
榜单背后的心理战
每一次大模型发布,榜单都是战场,也是烟幕。
OpenAI 会告诉你,GPT-5.5 在 coding、browser、frontier math、professional tasks 上如何超越前代。DeepSeek 会告诉你,V4-Pro 在开放模型中如何领先,如何接近甚至挑战闭源前沿模型。媒体会把这些数字排列成一张擂台图,仿佛 AI 进步可以像 NBA 球员得分一样一眼看懂。
但模型评测有一个越来越明显的问题:越是重要的能力,越难被单一 benchmark 捕捉。
智能体能力尤其如此。
一个真实的 agent 任务可能持续几小时,包含几十次工具调用,期间会遇到权限、网络、脏数据、过时文档、测试污染、用户需求变化。它不只是“回答对不对”,而是“是否能在混乱中维持方向感”。
GPT-5.5 的优势在于闭环:产品、工具、安全、推理基础设施由同一家公司整合,用户不需要自己拼装。DeepSeek V4 的优势在于可塑性:开放权重、长上下文和更低部署门槛,让它更容易进入各种非标准场景。
但各自的弱点也很清楚。
OpenAI 的闭环越强,用户越依赖它。模型能力、价格、访问权限、安全策略和产品方向,都掌握在一个平台手里。今天它是你的助手,明天它可能也是你的瓶颈。
DeepSeek 的开放越诱人,落地越考验工程能力。开放权重并不自动等于好产品。一百万 token 不自动等于好记忆。便宜推理不自动等于稳定服务。企业真正要买的,不是一个模型文件,而是可审计、可维护、可扩展、可负责的系统。
这就是怀疑论者的提醒:不要把发布会里的能力,直接等同于生产环境里的可靠性。
安全的阴影
GPT-5.5 的系统卡把安全放在中心位置,尤其是网络安全和生物相关能力。OpenAI 表示,它进行了完整的预部署安全评估、Preparedness Framework 评估、外部和内部 red teaming,并从近 200 个早期合作伙伴那里收集真实用例反馈。
这听起来像标准流程。
但它背后有一个越来越尖锐的问题:当模型变成能执行长流程任务的 agent,它的风险不再是“说错话”。
它可能真的做事。
会写代码的模型可以帮助防御者,也可以帮助攻击者。会研究生物数据的模型可以加速药物发现,也可能降低某些危险知识的门槛。会操作软件的模型可以替人处理重复劳动,也可能被用来自动化灰色甚至黑色流程。
OpenAI 的答案是更强的访问控制、更细的风险分类、更严格的监控和受信任访问机制。这符合封闭平台的治理逻辑:能力集中,责任也集中。
DeepSeek 的问题更复杂。开放模型的优点是创新扩散快,缺点是治理边界松。权重一旦开放,谁来限制高风险用途?谁来判断某个部署是否越界?谁来为下游微调后的模型行为负责?
这不是 DeepSeek 一家的问题,而是整个开放模型路线的问题。
开源世界擅长传播能力,不擅长分配责任。
中国速度与美国系统
DeepSeek V4 的发布之所以重要,不只是因为它又推出了一个强模型,而是因为它延续了 R1 之后的心理冲击。
2025 年,DeepSeek R1 让全球市场第一次意识到,前沿 AI 不一定只能由烧钱最多的美国公司定义。它的象征意义甚至超过了技术细节:如果中国公司能用更低成本做出接近前沿的模型,那么 AI 竞赛的门槛究竟在哪里?
2026 年的 V4 Preview 回答了另一个问题:DeepSeek 不是一次性奇迹,它正在把“低成本、开放、长上下文、国产硬件适配”组合成路线。
但 OpenAI 的 GPT-5.5 也提醒我们,美国前沿 AI 的核心优势并没有消失。它不只是模型强,而是系统强:融资能力、芯片合作、云端推理、企业客户、开发者工具、产品分发、安全团队和品牌信任,共同构成一台巨大的机器。
中国速度擅长把成本打下来,把开放生态推起来,把供应链压力转化为工程约束。
美国系统擅长把能力封装起来,把复杂性藏起来,把用户留在一个越来越完整的工作平台里。
这两种能力都真实。
也都不完美。
真正的分水岭
如果只问“GPT-5.5 和 DeepSeek V4 谁更强”,这个问题太窄了。
更有价值的问题是:AI 的下一阶段,到底由什么决定?
是单点智商吗?
是上下文长度吗?
是推理成本吗?
是 agent 工具链吗?
是安全治理吗?
答案可能是:全都要。
GPT-5.5 代表的是“可托付性”的竞争。它试图让用户相信,一个模型可以被交给真实工作,能规划、执行、纠错、收尾。它的核心卖点不是开源,也不是参数,而是完成度。
DeepSeek V4 代表的是“可占有性”的竞争。它让开发者和企业相信,前沿能力不一定必须租用自某个黑箱平台,也可以被下载、部署、适配、改造。它的核心卖点不是最强闭源体验,而是基础设施自由度。
一个问:你愿不愿意把工作交给我?
一个问:你愿不愿意把我装进你的工作里?
这就是二者真正的分水岭。
最后的房间
想象一间办公室。
桌上有两台机器。
第一台来自 OpenAI。你按下按钮,说出目标。它打开浏览器,读文件,写代码,查资料,生成表格,提醒你哪里有风险。它像一个安静但高效的同事,偶尔被安全策略拦住,偶尔让你觉得它太知道自己要去哪。
第二台来自 DeepSeek。它没有那么完整的外壳,却有巨大的记忆卷轴和可以拆开的骨架。工程师围着它接线、调参、部署、压测,把它塞进企业系统、国产芯片集群、研究工具和本地智能体框架里。它不像员工,更像一块正在发热的基础设施。
未来可能不是其中一台机器赢掉另一台。
更可能是:封闭系统负责把 AI 变成可靠服务,开放系统负责把 AI 变成普遍材料。前者让普通人更快用上智能,后者让更多人重新塑造智能。
而我们站在这两台机器之间,像站在两扇门前。
一扇门通向被托管的未来。
另一扇门通向可改造的未来。
真正的问题不是哪扇门更亮,而是当门后的智能开始替我们工作、记忆和决策时,我们还剩下多少能力,去理解它们正在怎样改变房间本身。
参考资料与延伸阅读:
OpenAI 官方发布:《Introducing GPT-5.5》,2026-04-23。https://openai.com/index/introducing-gpt-5-5/
OpenAI 官方系统卡:《GPT-5.5 System Card》,2026-04-23。https://openai.com/index/gpt-5-5-system-card/
Hugging Face 模型卡:deepseek-ai/DeepSeek-V4-Pro。https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
Hugging Face 模型集合:DeepSeek-V4。https://huggingface.co/collections/deepseek-ai/deepseek-v4
Hugging Face Blog:《DeepSeek-V4: a million-token context that agents can actually use》,2026-04-24。https://huggingface.co/blog/deepseekv4
Associated Press:《China’s DeepSeek rolls out a long-anticipated update of its AI model》,2026-04-24。https://apnews.com/article/d2ed33f2521917193616e061674d5f92
Reuters 报道转载:《China’s AI darling DeepSeek previews new model》,2026-04-24。https://www.investing.com/news/stock-market-news/chinas-ai-darling-deepseek-previews-new-model-4634553
The Verge:《OpenAI says its new GPT-5.5 model is more efficient and better at coding》,2026-04-23。https://www.theverge.com/ai-artificial-intelligence/917612/openai-gpt-5-5-chatgpt
The Verge:《China’s DeepSeek previews new AI model a year after jolting US rivals》,2026-04-24。https://www.theverge.com/ai-artificial-intelligence/918035/deepseek-preview-v4-ai-model

留下评论